ما هي ترجمة الذكاء الاصطناعي؟
ما هي ترجمة الذكاء الاصطناعي؟
فهرس المحتويات
-
من القواعد إلى التمثيلات المتعلمة - البيانات، الإشارات، والتكيف
- كيف تعمل أنظمة الإنتاج فعليًا
- قياس الجودة بدون أوهام
- السياق هو الملك
- الخطاب، الكمون، والاستخدام المباشر
- الخصوصية، الأمان، وقابلية التدقيق
- المصطلحات والفروق المحلية
- أنماط الفشل الشائعة—وكيف تتعامل الفرق معها
- دمج ترجمة الذكاء الاصطناعي في المنتجات
- الأخلاقيات والأصل
- الأسئلة المتكررة
ترجمة الذكاء الاصطناعي هي تحويل المعنى تلقائيًا من لغة إلى أخرى من خلال التعلم من البيانات بدلاً من ترميز قواعد النحو بشكل صارم. تعتبر الترجمة مشكلة تنبؤية: بالنظر إلى تسلسل من الرموز في لغة واحدة، يتم إنتاج تسلسل في الأخرى يحافظ على المعنى والنغمة والسجل والتنسيق. الميزة المميزة ليست فقط الرياضيات العصبية التي تولد الكلمات؛ بل النظام البيئي المحيط بالنماذج—خطوط البيانات، التحكم في المصطلحات، تقدير الجودة، حماية الخصوصية، سير العمل التحريري، والأدوات—التي تحول المخرجات الخام إلى تواصل متعدد اللغات موثوق.
من القواعد إلى التمثيلات المتعلمة
تطور أساليب الترجمة الآلية—من الأنظمة القائمة على القواعد إلى التمثيلات العصبية.
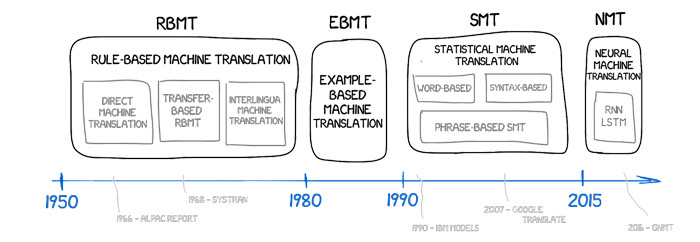
حاولت الأنظمة المبكرة ترميز القواعد يدويًا، من خلال رسم أجزاء الكلام وهياكل العبارات مع مجموعات قواعد معقدة. استبدلت الترجمة الآلية الإحصائية القواعد باحتمالات على الكلمات والعبارات المستخرجة من مجموعات متطابقة. المعيار الحالي هو الترجمة الآلية العصبية (NMT)، حيث تتعلم شبكة واحدة تمثيل الجملة المصدر كمتجهات كثيفة وفك تشفير جملة الهدف رمزًا تلو الآخر. عادةً ما يتم بناء NMT الحديثة على بنية المحول. يسمح آلية الانتباه للنموذج بوزن العلاقات عبر التسلسل بالكامل، مما يلتقط الاعتماد على المدى الطويل وترتيب الكلمات المرن. للحفاظ على القواميس قابلة للإدارة مع تغطية الانحرافات والأسماء النادرة، تعتمد تقسيم الكلمات على وحدات فرعية مثل ترميز بايت-باير أو SentencePiece.
توسع النماذج اللغوية الكبيرة (LLMs) هذا النهج. تم تدريبها على مجموعات بيانات متعددة اللغات ضخمة وتم ضبطها للتفكير العام، يمكنها الترجمة كقدرة من بين العديد، وتعامل المدخلات الفوضوية مثل الجمل الجزئية، والتنسيق المختلط، أو سجلات الدعم الدردشة. تعد مرونتها مفيدة، لكن التوليد المفتوح يجلب تحديات: إعادة صياغة حيث الدقة مطلوبة، أو تأكيدات واثقة من التفاصيل التي لم تكن موجودة أبدًا في المصدر. غالبًا ما تقترن أنظمة الإنتاج بمحرك NMT قوي مع مرحلة LLM تضبط النغمة بينما تحمي فك التشفير المقيد وإدخال المصطلحات الكلمات الحرجة.
تعد مجموعات البيانات المتوازية عالية الجودة العمود الفقري. توفر المحاكم، والبرلمانات، والترجمات، وبوابات المطورين، والمواقع الثنائية اللغة أزواج جمل متطابقة للتعلم تحت الإشراف. النص الأحادي اللغة مهم أيضًا. مع الترجمة العكسية، يتم ترجمة جمل اللغة المستهدفة إلى المصدر لتوليد أزواج إضافية، مما يحسن الطلاقة والتغطية في الاتجاهات ذات الموارد المنخفضة. تميل المتغيرات ذات التدريب الذاتي وأهداف القناة المزعجة إلى تحيز النماذج نحو المخرجات الطبيعية المستهدفة.
يعد التكيف مع المجال هو المكان الذي تصبح فيه الكفاءة العامة قيمة تجارية. يمكن أن يتعثر نموذج عام يؤدي بشكل جيد على الأخبار وصفحات الويب على نصوص قانونية، أو كتيبات سريرية، أو ملخصات براءات الاختراع. يمكن أن يؤدي الضبط الدقيق على كميات معتدلة من المواد في المجال—مدعومًا بقوائم المصطلحات وذاكرات الترجمة—إلى تغيير النمط والمصطلحات بشكل كبير. تتيح تقنيات الكفاءة في المعلمات (المهايئات، LoRA) للفرق الحفاظ على شخصيات متعددة في المجال دون إعادة تدريب النموذج بالكامل. بمرور الوقت، تصبح تصحيحات المحررين بعد التحرير والتقييمات إشارات تدريب: حلقات تغذية راجعة تحرك النظام نحو الصوت المفضل للمنظمة.
تبدأ عمليات النشر الحقيقية قبل أن يتم توليد أي رمز. يتم تطبيع المحتوى، تقسيمه، واكتشاف اللغة؛ يتم تحديد العناصر النائبة والتنسيق حتى يمكن الحفاظ عليها. يتم التعرف على السلاسل القابلة للتكرار بشكل كبير—تسميات واجهة المستخدم، رموز المنتجات، قوالب البريد الإلكتروني—مبكرًا وغالبًا ما تتجاوز الترجمة أو يتم تقييدها إلى متغيرات دقيقة. يقوم المحرك بترميز المصدر، وفك تشفير الهدف باستخدام بحث شعاعي أو أخذ عينات مقيدة، وإعادة فك الرموز لاستعادة الحالة والمسافات. تعيد المعالجة اللاحقة إدراج العلامات، والأرقام، والكيانات المسماة. يتنبأ نموذج تقدير الجودة بالثقة، ويوجه المقاطع ذات الثقة المنخفضة إلى المحررين البشريين بينما يسمح للمقاطع ذات الثقة العالية بالنشر عندما تكون الكمون مهمًا.
تحدد بعض العوامل خصائص الترجمة:
- فك التشفير المقيد: يجب أن تظهر المصطلحات المطلوبة، مع مرونة في الانحراف للغات الغنية مورفولوجيًا.
- إدخال المصطلحات والذاكرات: توجه المتغيرات المفضلة والجمل المعتمدة سابقًا المخرجات نحو الاتساق.
- توجيه المخاطر: يحدد تقدير الجودة العتبات للنشر التلقائي مقابل التحرير اللاحق، موازنًا بين التكلفة، والسرعة، والدقة.
توفر أدوات الترجمة المدعومة بالكمبيوتر قمرة القيادة للمحررين. تتحدث الاقتراحات أثناء الكتابة؛ تقيس الفروق جهد التحرير اللاحق؛ تظهر مقاييس ضغط المفاتيح والوقت الأماكن التي تكافح فيها النماذج. تُعلم هذه الآثار اختيار بيانات التدريب وتحديثات النموذج. تعتبر الأدوات ضرورية: يتم تتبع الكمون، والإنتاجية، وأنواع الأخطاء، وجهد المحرر حسب المنطقة والمجال. يمكن للفرق التعمق من مقياس لوحة المعلومات إلى الجملة الدقيقة التي تسببت في تراجع.
توفر المقاييس التلقائية تغذية راجعة سريعة. تقيس BLEU وchrF تداخل n-gram أو التشابه على مستوى الحروف؛ تقيس المقاييس المتعلمة مثل COMET بشكل أفضل مع الأحكام البشرية من خلال مقارنة المخرجات والمراجع عبر مشفرات عصبية. يتنبأ تقدير الجودة بدون مرجع بدرجة وحتى نطاقات الأخطاء باستخدام المصدر والافتراض فقط، مما يمكّن من التوجيه في الوقت الحقيقي. ومع ذلك، لا تحل أي من هذه محل المراجعة البشرية. يتحقق اللغويون من الكفاية (المعنى محفوظ) والطلاقة (الطبيعية)، ويطبقون قوائم مراجعة محددة حسب المجال: هل تحترم المخرجات صوت العلامة التجارية، وصياغة قانونية، وكلمات التحذير، وقواعد المنطقة للأسماء، والعناوين، والأرقام العشرية؟ تمزج البرامج الجيدة بين لوحات المعلومات الآلية والتقييمات البشرية العمياء الدورية، المزروعة بظواهر صعبة مثل الاتفاق بعيد المدى، والعبارات الاصطلاحية، واللغة المختلطة.
تعد العديد من أخطاء الترجمة فشلًا في السياق. تتطلب الضمائر، والحذف، وروابط الخطاب وعيًا يتجاوز الجملة. تقوم النماذج على مستوى الوثيقة بتكييف الجمل المحيطة؛ تسترجع الترجمة المعززة المقاطع ذات الصلة من وقت سابق في الوثيقة، أو أدلة الأسلوب، أو سجلات التذاكر وتنتبه إليها أثناء فك التشفير. في دردشة الدعم، يحترم فك التشفير التدريجي أدوار المتحدثين ويحافظ على سجل متسق لكل مشارك. في نصوص التسويق، يمكن أن تكون الخيارات الصغيرة—الألقاب، والرسمية، والإيقاع—أكثر أهمية من الدقة الحرفية، وغالبًا ما تحكمها أوراق الأنماط وقواعد محلية محددة يتم إدخالها في المطالبات أو قيود فك التشفير.
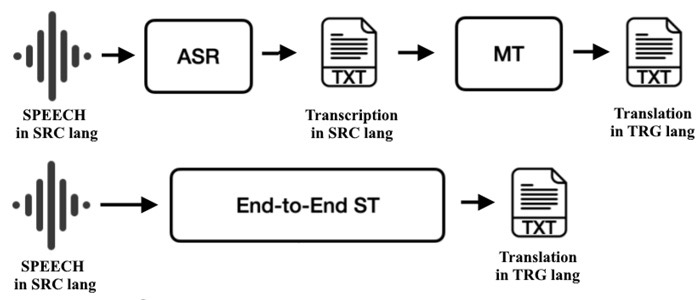
الخطاب، الكمون، والاستخدام المباشر
تقدم ترجمة الخطاب توقيتًا وإيقاعًا. تؤدي الأنظمة المتسلسلة ASR → نص MT → TTS؛ يمكن ضبط كل مرحلة بشكل منفصل، وتسمح الطوابع الزمنية بمحاذاة الترجمة. تقوم الترجمة من الصوت إلى النص من النهاية إلى النهاية بربط الصوت مباشرة بنص لغة أخرى، مما يقلل من الأخطاء المتراكمة وأحيانًا يحافظ على الصياغة بشكل أفضل. تؤكد السيناريوهات المباشرة على الكمون. تقوم الأنظمة بتقسيم الصوت إلى قطع صغيرة، وتقديم افتراضات جزئية بسرعة، وتعديلها مع زيادة الثقة. يحسن التعامل الدقيق مع علامات الترقيم وعدم الطلاقة من قابلية القراءة في الترجمة ويمنع الغموض في التعليمات حيث يمكن أن يغير الفاصلة المفقودة المعنى.
الخصوصية، الأمان، وقابلية التدقيق
تتعلق الترجمة غالبًا بمحتوى حساس: رسائل المستخدم، مستندات داخلية، سجلات صحية، عقود. تستجيب عمليات النشر بالتحكم الفني والإجرائي. يتم تشفير المدخلات والمخرجات أثناء النقل وفي حالة السكون؛ يتم تقليل فترات الاحتفاظ؛ يتم إخفاء المعلومات الشخصية القابلة للتحديد قبل المعالجة وإعادة إدراجها بعد ذلك. تحدد ضوابط الوصول من يمكنه عرض المحتوى الخام ومخرجات النموذج. بالنسبة للصناعات المنظمة، تسجل سجلات التدقيق إصدارات النموذج، والمطالبات، ومعلمات فك التشفير، وإجراءات المحرر، وخطوات الموافقة لإعادة بناء كيفية وصول جملة إلى النشر. تكشف فلاتر المحتوى عن الفئات الخطرة مثل الكراهية أو إيذاء النفس؛ قد تتطلب المقاطع المميزة مراجع بشرية إضافية حتى لو كانت اللغة نفسها تبدو طليقة.
تعد المصطلحات غالبًا المكان الذي تلتقي فيه الدقة بالهوية. قد تصر فريق المنتج على "تسجيل الدخول" بدلاً من "تسجيل الدخول"، أو على صياغة محددة لفقرة الضمان. يفرض النظام هذه الخيارات من خلال قيود صارمة، وتحاملات ناعمة، وفحوصات تحقق تجري بعد التوليد. توفر ذاكرات الترجمة تطابقات دقيقة وغير دقيقة بحيث تظل المحتويات المتكررة متسقة ويتجنب المحررون إعادة العمل. تضيف تفاصيل المنطقة التي تبدو ثانوية—ترتيب العناوين، فواصل الأرقام العشرية، تنسيقات التواريخ، وتكبير العناوين—إلى المصداقية. تقدم الأسماء حالات خاصة: تختلف سياسات التحويل حسب السوق، ويتم الاحتفاظ ببعض العلامات التجارية دائمًا في النص اللاتيني بينما يتم توطين أخرى.
أنماط الفشل الشائعة—وكيف تتعامل الفرق معها
-
انحراف الأرقام والرموز أثناء التوليد. تضمن آليات النسخ والمراجعين اللاحقين بقاء رموز المنتجات، والأسعار، وتحويلات الوحدات سليمة. - سلاسل قصيرة غامضة. أضف بيانات وصفية (اسم الشاشة، الجمهور) لتوضيح أو توجيه إلى البشر؛ احتفظ بقواميس صغيرة لمكونات واجهة المستخدم.
- إعادة صياغة مفرطة من LLMs العامة. استخدم فك التشفير المقيد، وفرض المصطلحات، وتمريرة NMT المضبوطة حسب المجال قبل تحسين الأسلوب.
- بيانات تدريب مشوشة أو غير متطابقة. قم بتنظيم مجموعات البيانات، وتطابق بعناية، وعزل المصادر التي تقدم أخطاء منهجية.
- إهمال تفضيلات المنطقة. حافظ على أدلة أسلوب لكل منطقة؛ اختبر المتغيرات مع المراجعين الأصليين؛ تجنب الإعدادات العالمية التي تتجاوز بهدوء المعايير المحلية.
دمج ترجمة الذكاء الاصطناعي في المنتجات
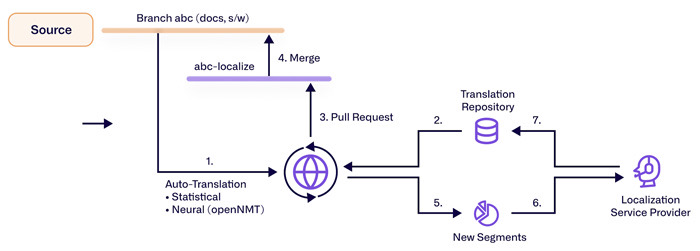
تشكل خيارات الهندسة النتائج بقدر ما تشكل اختيار النموذج. تقدم واجهات برمجة التطبيقات السحابية تغطية لغوية واسعة وقدرة مرنة؛ توفر النماذج المستضافة ذاتيًا التحكم وإدارة بيانات أكثر صرامة؛ تقوم الهجينة بتوجيه المحتوى الحساس أو عالي المخاطر داخليًا وإرسال المواد منخفضة المخاطر إلى الخارج. تحسن المعالجة الدفعة الإنتاجية للدفعات الكبيرة؛ تقلل واجهات برمجة التطبيقات المتدفقة من الكمون المدرك في الدردشة والإعدادات المباشرة. تحمي مفاتيح التكرار وإعادة المحاولة من النشر المكرر. تعتبر القابلية للرؤية غير قابلة للتفاوض: قم بتخزين معرفات مشفرة للمدخلات والمخرجات، وقم بتعليق الأخطاء مع الفئات، وقدم لوحات معلومات تجمع بين المقاييس التلقائية، والدرجات البشرية، ومؤشرات الأداء الرئيسية التجارية (وقت التحول، التكلفة لكل كلمة، جهد التحرير اللاحق).
لراحة المطورين، اجعل المصطلحات وذاكرة الترجمة خدمات من الدرجة الأولى مع واجهات برمجة تطبيقات واضحة بدلاً من جداول بيانات متفرقة. قم ببناء خط أنابيب محتوى يبدو مثل أي نظام بيانات حديث: قوائم، وعمال، ومتاجر ميزات للقواميس، ووظائف تقييم تعمل ليلاً على مجموعات اختبار ثابتة. أنشئ بوابات للمجالات عالية المخاطر حيث يتم تعطيل النشر التلقائي بموجب السياسة. وعند استخدام LLMs، اعتبر المطالبات كإعدادات مع إصدار، وسجلات التغيير، ومسارات التراجع؛ يمكن أن يؤدي تعديل صغير في المطالبة إلى تغيير النغمة بطرق غير متوقعة.
تتعلم تقنيات اللغة من البيانات التي تعكس أنماط العالم، بما في ذلك تحيزاتها. تقلل التنظيم، وإزالة التكرار، والتدقيق من الآثار الضارة. عند ترجمة المحتوى الذي ينشئه المستخدم، يجب الإفصاح عن استخدام الترجمة الآلية حيثما كان ذلك مناسبًا واحترام الموافقة. تعتبر أصول البيانات مهمة: يجب أن تعرف الفرق من أين نشأت مجموعات بيانات التدريب والتعديل، وما هي التراخيص التي تنطبق، وما هي الالتزامات التي تتبع. تعتبر إمكانية الوصول جزءًا من المهمة: قد تكون المتغيرات بلغة بسيطة ضرورية في بعض السياقات، ويجب أن تحترم الأنظمة تلك المتطلبات بنفس الصرامة التي تحترم بها نغمة العلامة التجارية.
إذن، فإن ترجمة الذكاء الاصطناعي ليست مجرد استدعاء نموذج واحد ولكنها نظام منسق. تتعلم النماذج الهيكل عبر اللغات؛ توجهها أصول البيانات والقيود؛ يوفر تقدير الجودة والمحررون البشريون الفرامل والتوجيه؛ تجعل طبقات الخصوصية والتدقيق العملية موثوقة؛ تظهر الأدوات أين يمكن تحسينها بعد ذلك. عندما يتم تصميم تلك الأجزاء للعمل معًا، لا تتحرك المنظمات فقط بالكلمات بين اللغات—بل تحافظ على النية، والوضوح، والهوية عبر المنتجات، والأسواق، والوسائط على النطاق الذي تتطلبه الاتصالات الحديثة.
تعتمد أنظمة ترجمة الذكاء الاصطناعي على هياكل التعلم العميق—خاصة المحولات—لنمذجة الجمل الكاملة كتمثيلات سياقية. بدلاً من الاعتماد على احتمالات على مستوى الكلمات أو قواعد النحو المعرفة يدويًا، تتعلم الهياكل اللغوية الضمنية من مجموعات بيانات ثنائية اللغة كبيرة. يسمح لها ذلك بالتعميم عبر المجالات والتعامل مع المدخلات العامية أو غير النحوية بشكل أكثر فعالية من الأنظمة السابقة القائمة على القواعد أو الإحصائية.
تعد بيانات التدريب أساس قدرة مترجم الذكاء الاصطناعي. تؤثر مجموعات البيانات النظيفة، والمحددة حسب المجال، والمتطابقة بشكل جيد بشكل مباشر على الدقة والنغمة. يمكن أن تؤدي الضوضاء، أو عدم التطابق، أو عدم التوافق مع المجال إلى نشر أخطاء منهجية في المخرجات. بالنسبة للتطبيقات ذات المخاطر العالية مثل الترجمة القانونية أو الطبية، غالبًا ما يتم دمج مجموعات البيانات المنسقة وقوائم المصطلحات المعتمدة بشريًا في مراحل الضبط الدقيق للحفاظ على الدقة والتحكم في المصطلحات.
تستخدم خطوط أنابيب الترجمة المؤسسية عادةً إدخال المصطلحات وذاكرات الترجمة لضمان اتساق الصياغة. أثناء فك التشفير، يمكن للنظام فرض المصطلحات المطلوبة ديناميكيًا من خلال فك التشفير المقيد. تدعم هذه القيود قواعد بيانات لغوية وأنظمة إدارة المصطلحات التي تحدد المفردات المعتمدة حسب العلامة التجارية، والمنطقة، والسياق التنظيمي. تقيس أدوات التقييم المستمرة مدى احترام المحرك لتلك المصطلحات عبر التحديثات.
يتم تقليل الكمون من خلال فك التشفير التدريجي، ومعالجة الصوت المجزأة، وتحسينات الاستدلال على الجهاز. بدلاً من الانتظار للحصول على مدخلات كاملة، تولد النماذج المتدفقة افتراضات جزئية تتكرر مع وصول سياق جديد. في ترجمة الخطاب المباشرة، تتاجر الأنظمة بهامش دقة صغير من أجل الاستجابة، مع إعطاء الأولوية للتوقيت الطبيعي ومحاذاة المقاطع. تقلل تقنيات تقليل النموذج وتسريع الأجهزة من تأخيرات المعالجة.
تشمل التحديات الرئيسية انتشار التحيز، وخصوصية البيانات، وقابلية التتبع. غالبًا ما تعكس مجموعات بيانات التدريب التحيزات الاجتماعية أو الثقافية التي يمكن أن تظهر مرة أخرى في المخرجات المترجمة. تقوم عمليات النشر المسؤولة بإخفاء البيانات الحساسة، وتنفيذ سجلات التدقيق لقرارات الترجمة، والسماح بمراجعة بشرية للمحتوى ذي التأثير العالي. أصبحت الشفافية في أصول البيانات واختبارات التحيز المستمرة متطلبات قياسية لخطوط أنابيب ترجمة الذكاء الاصطناعي المتوافقة.