Що таке переклад ШІ?
Що таке переклад ШІ?
Зміст
-
Від правил до навчальних представлень - Дані, сигнали та адаптація
- Як насправді працюють виробничі системи
- Вимірювання якості без ілюзій
- Контекст — це король
- Мова, затримка та живе використання
- Конфіденційність, безпека та аудит
- Термінологія та нюанси локалізації
- Загальні режими збоїв — і як команди їх пом'якшують
- Інтеграція перекладу ШІ в продукти
- Етика та походження
- Питання та відповіді
Переклад ШІ — це автоматизоване відтворення значення з однієї мови на іншу, навчаючись на даних, а не жорстко кодувати граматичні правила. Він розглядає переклад як задачу прогнозування: маючи послідовність токенів однією мовою, потрібно створити послідовність іншою, яка зберігає сенс, тон, реєстр і форматування. Відмінною рисою є не лише нейронна математика, що генерує слова; це екосистема навколо моделей — канали даних, контроль термінології, оцінка якості, захист конфіденційності, робочі процеси редакторів та інструменти — які перетворюють сирі виходи на надійну багатомовну комунікацію.
Від правил до навчальних представлень
Еволюція підходів до машинного перекладу — від систем на основі правил до нейронних представлень.
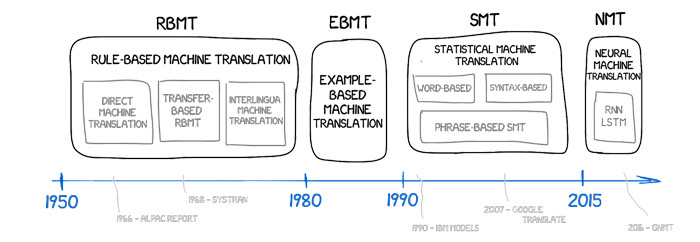
Ранні системи намагалися вручну закодувати граматики, відображаючи частини мови та структури фраз з допомогою складних наборів правил. Статистичний машинний переклад замінив правила на ймовірності слів і фраз, витягнутих з узгоджених корпусів. Поточний стандарт — нейронний машинний переклад (NMT), де одна мережа навчається представляти вихідне речення як щільні вектори та декодувати цільове речення токен за токеном. Сучасний NMT зазвичай побудований на архітектурі Transformer. Його механізм уваги дозволяє моделі зважувати зв'язки по всій послідовності, захоплюючи довгострокові залежності та гнучкий порядок слів. Щоб зберегти словники керованими, покриваючи відмінювання та рідкі імена, токенізація спирається на підсловні одиниці, такі як Byte-Pair Encoding або SentencePiece.
Великі мовні моделі (LLMs) розширюють цей підхід. Навчені на величезних багатомовних корпусах і налаштовані для загального міркування, вони можуть перекладати як одну з багатьох можливостей, обробляючи неохайний вхід, такий як часткові речення, змішане розмітка або балакучі журнали підтримки. Їхня універсальність корисна, але відкритий генерація приносить виклики: перефразування, де потрібна точність, або впевнені твердження про деталі, яких ніколи не було в джерелі. Виробничі системи часто поєднують потужний NMT-двигун з етапом LLM, який коригує тон, в той час як обмежене декодування та ін'єкція термінів захищають критичні формулювання.
Високоякісні паралельні корпуси є основою. Судові, парламентські, субтитри, портали для розробників та двомовні веб-сайти надають узгоджені пари речень для контрольованого навчання. Одномовний текст також важливий. За допомогою зворотного перекладу речення цільовою мовою перекладаються на вихідну, щоб синтезувати додаткові пари, покращуючи плавність і покриття в напрямках з низькими ресурсами. Варіанти самонавчання та цілі шумового каналу ще більше сприяють моделям до природного цільового виходу.
Адаптація до домену — це те, де загальна компетенція стає бізнес-цінністю. Загальна модель, яка добре працює на новинах і веб-сторінках, може зазнати невдачі на юридичних шаблонах, клінічних листівках або абстрактах патентів. Тонке налаштування навіть на помірних обсягах матеріалів у домені — доповнене списками термінів та пам'яттю перекладу — може суттєво змінити стиль і термінологію. Техніки з ефективним використанням параметрів (адаптери, LoRA) дозволяють командам підтримувати кілька доменних особистостей без повторного навчання всієї моделі. З часом корекції та оцінки редакторів стають навчальними сигналами: зворотні зв'язки, які рухають систему до бажаного голосу організації.
Як насправді працюють виробничі системи
Справжні розгортання починаються до того, як буде згенеровано жоден токен. Контент нормалізується, сегментується та визначається мова; місця для заповнення та розмітка ідентифікуються, щоб їх можна було зберегти. Дуже повторювані рядки — UI-мітки, коди продуктів, шаблони електронних листів — рано розпізнаються і часто обходять переклад або обмежуються точними варіантами. Двигун кодує вихідне, декодує цільове за допомогою пошуку променя або обмеженого вибірки, і детокенізує, щоб відновити регістрацію та пробіли. Постобробка повторно вставляє теги, числа та названі сутності. Модель оцінки якості прогнозує впевненість, направляючи сегменти з низькою впевненістю до людських редакторів, дозволяючи публікувати сегменти з високою впевненістю, коли важлива затримка.
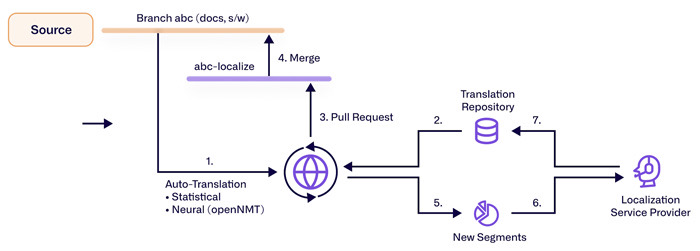
Кілька важелів визначають характеристики перекладу:
- Обмежене декодування: необхідні терміни повинні з'являтися, з морфологічною гнучкістю для мов з багатими відмінюваннями.
- Ін'єкція термінів та пам'яті: переважні варіанти та раніше затверджені речення спрямовують виходи до узгодженості.
- Маршрутизація ризиків: оцінка якості встановлює пороги для автоматичної публікації проти пост-редагування, балансуючи витрати, швидкість і точність.
Інструменти комп'ютерного перекладу забезпечують кабіну для редакторів. Пропозиції оновлюються в міру введення; дифі вимірюють зусилля пост-редагування; метрики натискання клавіш і часу показують, де моделі стикаються з труднощами. Ці сліди інформують вибір навчальних даних і оновлення моделей. Інструментація є необхідною: затримка, пропускна здатність, типи помилок та зусилля редакторів відстежуються за локаллю та доменом. Команди можуть переходити від метрики на панелі приладів до точного речення, яке викликало регресію.
Автоматичні метрики забезпечують швидкий зворотний зв'язок. BLEU та chrF вимірюють перекриття n-грам або подібність на рівні символів; навчальні метрики, такі як COMET, краще корелюють з людськими оцінками, порівнюючи виходи та посилання через нейронні кодувальники. Оцінка якості без посилань прогнозує бал і навіть діапазони помилок, використовуючи лише вихідні дані та гіпотезу, що дозволяє маршрутизувати в реальному часі. Проте жодна з цих метрик не замінює людський огляд. Лінгвісти перевіряють адекватність (збереження значення) та плавність (природність), і вони застосовують специфічні для домену контрольні списки: чи поважає вихідний текст голос бренду, юридичну формулювання, формулювання протипоказань та локальні конвенції для імен, адрес та десяткових дробів? Хороші програми поєднують автоматизовані панелі з періодичними сліпими людськими оцінками, засіяними складними явищами, такими як узгодження на великій відстані, ідіоми та змішаний сленг.
Багато помилок перекладу є невдачами контексту. Займенники, еліпсиси та зв'язки дискурсу вимагають усвідомлення за межами речення. Моделі на рівні документів умовно залежать від сусідніх речень; переклад з підкріпленням витягує відповідні сегменти з раніше в документі, стилістичних посібників або історій квитків і враховує їх під час декодування. У чаті підтримки поступове декодування поважає черги спікерів і підтримує послідовний реєстр для кожного учасника. У маркетингових текстах невеликі вибори — почесні титули, формальність, ритм — можуть мати більше значення, ніж буквальна вірність, і ними часто керують стилістичні таблиці та специфічні для локалізації правила, які вводяться в підказки або обмеження декодування.
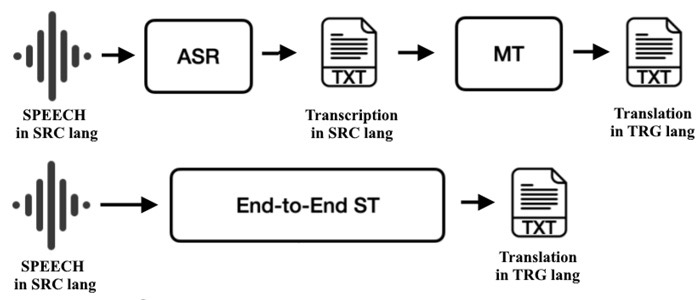
Мова, затримка та живе використання
Переклад мови вводить таймінг і просодію. Каскадні системи виконують ASR → текстовий MT → TTS; кожен етап можна налаштувати окремо, а часові мітки дозволяють вирівнювати субтитри. Переклад мови в текст безпосередньо відображає аудіо в текст іншої мови, зменшуючи накопичувальні помилки і іноді краще зберігаючи формулювання. Живі сценарії підкреслюють затримку. Системи сегментують аудіо на невеликі частини, швидко надають часткові гіпотези та коригують їх у міру зростання впевненості. Уважна пунктуація та обробка невизначеності покращують читабельність у підписах і запобігають неоднозначності в інструкціях, де відсутня кома може змінити значення.
Конфіденційність, безпека та аудит
Переклад часто стосується чутливого контенту: повідомлень користувачів, внутрішніх документів, медичних записів, контрактів. Розгортання реагують технічними та процедурними контролями. Входи та виходи шифруються під час передачі та зберігання; вікна зберігання мінімізуються; особисто ідентифіковану інформацію маскують перед обробкою та повторно вставляють після. Контроль доступу обмежує, хто може переглядати сирий контент та виходи моделі. Для регульованих галузей журнали аудиту фіксують версії моделей, підказки, параметри декодування, дії редакторів та етапи затвердження, щоб відтворити, як речення дійшло до публікації. Фільтри контенту виявляють ризиковані категорії, такі як ненависть або самопошкодження; позначені фрагменти можуть вимагати додаткового людського рецензента, навіть якщо сама мова виглядає плавною.
Термінологія та нюанси локалізації
Термінологія часто є місцем, де правильність зустрічається з ідентичністю. Команда продукту може наполягати на “Увійти” замість “Логін”, або на конкретній формулюванні для пункту гарантії. Система забезпечує ці вибори через жорсткі обмеження, м'які упередження та перевірки валідації, які виконуються після генерації. Пам'яті перекладу постачають точні та нечіткі відповідності, щоб повторюваний контент залишався узгодженим, а редактори уникали повторної роботи. Деталі локалізації, які здаються незначними — порядок адрес, десяткові роздільники, формати дат, капіталізація заголовків — складаються в довіру. Імена представляють особливі випадки: політики транслітерації відрізняються за ринком, і деякі бренди завжди зберігаються в латинському скрипті, тоді як інші локалізуються.
Загальні режими збоїв — і як команди їх пом'якшують
-
Числа та коди, що зміщуються під час генерації. Механізми копіювання та пост-валідатори забезпечують збереження кодів продуктів, цін та конверсій одиниць. - Неоднозначні короткі рядки. Додайте метадані (ім'я екрану, аудиторія) для розрізнення або маршрутизації до людей; зберігайте міні-глосарії для компонентів UI.
- Перепарафразування від загальних LLM. Використовуйте обмежене декодування, забезпечення термінів та налаштований на домен NMT перед стилістичним вдосконаленням.
- Шумні або невирівняні навчальні дані. Куруйте корпуси, уважно вирівнюйте та карантинуйте джерела, які вводять систематичні помилки.
- Ігнорування уподобань локалізації. Підтримуйте стилістичні посібники для кожної локалізації; тестуйте варіанти з рідними рецензентами; уникайте глобальних налаштувань, які безшумно переважають місцеві норми.
Інтеграція перекладу ШІ в продукти
Вибір інженерії формує результати так само, як і вибір моделі. Хмарні API пропонують широкий мовний охоплення та еластичну ємність; самостійно розміщені моделі забезпечують контроль та більш жорстке управління даними; гібриди маршрутизують чутливий або високий ризик контенту внутрішньо та надсилають матеріали з низьким ризиком назовні. Пакетна обробка покращує пропускну здатність для великих обсягів; стрімінгові API зменшують сприйману затримку в чатах та живих налаштуваннях. Ключі ідемпотентності та повторні спроби захищають від дублювання публікацій. Спостережуваність є незаперечною: зберігайте хешовані ідентифікатори для входів та виходів, анотуйте помилки категоріями та відображайте панелі, які поєднують автоматичні метрики, людські оцінки та бізнес-KPI (час обробки, вартість за слово, зусилля пост-редагування).
Для зручності розробників зробіть термінологію та пам'ять перекладу першокласними послугами з чіткими API, а не розкиданими електронними таблицями. Створіть контентний конвеєр, який виглядає як будь-яка сучасна система даних: черги, працівники, сховища функцій для глосаріїв та оцінювальні завдання, які виконуються щовечора на статичних тестових наборах. Створіть ворота для високих ризикових доменів, де автоматична публікація заборонена політикою. І коли ви використовуєте LLM, розглядайте підказки як конфігурацію з версіями, журналами змін та шляхами відкату; невелике коригування підказки може змінити тон несподіваними способами.
Мовні технології навчаються на даних, які відображають патерни світу, включаючи його упередження. Курування, видалення дублікатів та аудит зменшують шкідливі артефакти. При перекладі контенту, створеного користувачами, розкривайте використання машинного перекладу, де це доречно, і поважайте згоду. Походження даних має значення: команди повинні знати, звідки походять корпуси для навчання та тонкого налаштування, які ліцензії застосовуються та які зобов'язання слідують. Доступність є частиною завдання: варіанти простої мови можуть бути необхідні в деяких контекстах, і системи повинні дотримуватися цих вимог так само суворо, як вони дотримуються тону бренду.
Отже, переклад ШІ — це не один виклик моделі, а координована система. Моделі вивчають крослінгвістичну структуру; активи даних та обмеження керують ними; оцінка якості та людські редактори забезпечують гальма та керування; шари конфіденційності та аудиту роблять процес надійним; інструментація показує, де покращити далі. Коли ці елементи спроектовані для спільної роботи, організації не просто переміщують слова між мовами — вони зберігають намір, ясність та ідентичність через продукти, ринки та медіа в масштабах, які вимагає сучасна комунікація.
Системи перекладу ШІ покладаються на архітектури глибокого навчання — особливо Transformers — для моделювання цілих речень як контекстуальних представлень. Замість того, щоб покладатися на ймовірності на рівні слів або вручну визначені граматичні правила, вони вивчають імпліцитні лінгвістичні структури з великих паралельних корпусів. Це дозволяє їм узагальнювати по доменах і ефективніше обробляти розмовний або граматично неправильний вхід, ніж раніше системи на основі правил або статистичні системи.
Навчальні дані є основою можливостей перекладача ШІ. Чисті, специфічні для домену та добре узгоджені двомовні корпуси безпосередньо впливають на точність і тон. Шум, невідповідності або невідповідність домену можуть поширювати систематичні помилки у виході. Для високих ставок, таких як юридичний або медичний переклад, часто інтегруються кураторські набори даних та перевірені людьми глосарії на етапах тонкого налаштування, щоб підтримувати точність та контроль термінології.
Підприємницькі перекладні конвеєри зазвичай використовують ін'єкцію термінів та пам'яті перекладу, щоб гарантувати узгоджене формулювання. Під час декодування система може динамічно забезпечувати необхідні терміни через обмежене декодування. Ці обмеження підтримуються лінгвістичними базами даних та системами управління термінологією, які визначають затверджений словник за брендом, локаллю та регуляторним контекстом. Інструменти безперервної оцінки вимірюють, наскільки послідовно двигун дотримується цих термінів під час оновлень.
Затримка мінімізується за допомогою поступового декодування, обробки аудіо частинами та оптимізації висновків на пристрої. Замість того, щоб чекати на повний вхід, стрімінгові моделі генерують часткові гіпотези, які уточнюються, коли надходить новий контекст. У живому перекладі мови системи жертвують невеликим запасом точності заради швидкості, пріоритетуючи природний таймінг та вирівнювання сегментів. Квантизація моделі та апаратне прискорення ще більше зменшують затримки обробки.
Ключові виклики включають поширення упереджень, конфіденційність даних та відстежуваність. Навчальні корпуси часто відображають соціальні або культурні упередження, які можуть з'явитися в перекладеному виході. Відповідальні розгортання анонімізують чутливі дані, впроваджують журнали аудиту для рішень перекладу та дозволяють людський огляд контенту з високим впливом. Прозорість у походженні даних та постійне тестування упереджень стають стандартними вимогами для відповідних конвеєрів перекладу ШІ.