什麼是 AI 翻譯?
什麼是 AI 翻譯?
內容目錄
-
從規則到學習表示 - 數據、信號和適應
- 生產系統實際如何運作
- 無幻覺地測量質量
- 上下文為王
- 語音、延遲和實時使用
- 隱私、安全性和可審計性
- 術語和地方細微差別
- 常見失敗模式—及其團隊如何減輕
- 將 AI 翻譯整合到產品中
- 倫理和來源
- 常見問題
AI 翻譯是通過從數據中學習而非硬編碼語法規則,將一種語言的意義自動轉換為另一種語言。它將翻譯視為一個預測問題:給定一種語言中的一系列標記,生成另一種語言中保持意義、語調、註冊和格式的序列。其獨特之處不僅在於生成單詞的神經數學,而在於圍繞模型的生態系統——數據管道、術語控制、質量估計、隱私保護、編輯工作流程和儀器——將原始輸出轉化為可靠的多語言交流。
機器翻譯方法的演變——從基於規則的系統到神經表示。
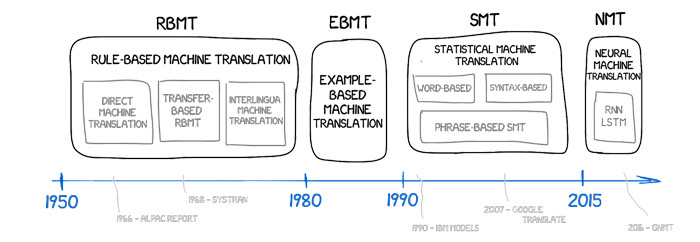
早期系統試圖手動編碼語法,通過複雜的規則集映射詞性和短語結構。統計機器翻譯用從對齊語料庫中提取的單詞和短語的概率取代了規則。當前的標準是神經機器翻譯(NMT),其中單個網絡學會將源句表示為密集向量,並逐個解碼目標句。現代 NMT 通常基於 Transformer 架構。其注意力機制使模型能夠權衡整個序列中的關係,捕捉長距離依賴和靈活的單詞順序。為了保持詞彙的可管理性,同時涵蓋屈折和稀有名稱,分詞依賴於子詞單位,如字節對編碼或 SentencePiece。
大型語言模型(LLMs)擴展了這種方法。它們在大量多語言語料庫上進行訓練,並針對一般推理進行調整,可以作為多種能力之一進行翻譯,處理像部分句子、混合標記或聊天支持日誌等雜亂的輸入。它們的多功能性是有幫助的,但開放式生成帶來了挑戰:在需要精確的地方進行意譯,或自信地聲稱源中從未出現的細節。生產系統通常將強大的 NMT 引擎與 LLM 階段配對,調整語調,同時受限解碼和術語注入保護關鍵措辭。
高質量的平行語料庫是基礎。法院、議會、字幕、開發者門戶和雙語網站提供對齊的句子對以進行監督學習。單語文本也很重要。通過反向翻譯,目標語言句子被翻譯回源語言,以合成額外的對,改善低資源方向的流暢性和覆蓋範圍。自我訓練變體和噪聲通道目標進一步使模型偏向自然的目標輸出。
領域適應是通用能力變成商業價值的地方。對新聞和網頁表現良好的通用模型在法律範本、臨床小冊子或專利摘要上可能會失敗。在即使是適度的領域材料上進行微調——通過術語列表和翻譯記憶增強——可以顯著改變風格和術語。參數高效技術(適配器、LoRA)使團隊能夠在不重新訓練整個模型的情況下維持多個領域個性。隨著時間的推移,後編輯的修正和評分成為訓練信號:反饋循環使系統朝向組織的首選聲音移動。
實際部署在生成任何標記之前就開始。內容被標準化、分段和語言檢測;佔位符和標記被識別,以便保留。高度可重複的字符串——用戶界面標籤、產品代碼、電子郵件模板——被及早識別,並經常跳過翻譯或被限制為精確變體。引擎編碼源,使用束搜索或受限抽樣解碼目標,並去標記化以恢復大小寫和間距。後處理重新插入標籤、數字和命名實體。質量估計模型預測信心,將低信心段路由到人類編輯,而允許高信心段在延遲重要時發布。
幾個杠杆定義了翻譯特徵:
- 受限解碼:必須出現的術語,對於形態豐富的語言具有屈折靈活性。
- 術語注入和記憶:首選變體和先前批准的句子引導輸出朝向一致性。
- 風險路由:質量估計設置自動發布與後編輯的閾值,平衡成本、速度和準確性。
計算機輔助翻譯工具為編輯提供了控制台。建議在他們輸入時更新;差異測量後編輯工作量;按鍵和時間指標顯示模型掙扎的地方。這些痕跡為訓練數據選擇和模型更新提供信息。儀器是必不可少的:延遲、吞吐量、錯誤類型和編輯工作量按地區和領域進行跟踪。團隊可以從儀表板指標深入到導致回歸的確切句子。
自動指標提供快速反饋。BLEU 和 chrF 測量 n-gram 重疊或字符級相似性;學習指標如 COMET 通過通過神經編碼器比較輸出和參考來更好地與人類判斷相關。無參考質量估計僅使用源和假設預測分數甚至錯誤範圍,實現實時路由。然而,這些都無法取代人類審查。語言學家檢查充分性(意義保留)和流暢性(自然性),並應用特定領域的檢查清單:輸出是否尊重品牌聲音、法律措辭、禁忌措辭以及名稱、地址和小數的地方慣例?好的程序將自動儀表板與定期盲人評估相結合,並以困難現象(如長距離一致性、成語和混合俚語)為種子。
許多翻譯錯誤是上下文失敗。代詞、省略和話語鏈接需要超越句子的意識。文檔級模型對周圍句子進行條件處理;檢索增強翻譯從文檔早期提取相關段落,並在解碼過程中關注它們。在支持聊天中,增量解碼尊重說話者的轉換,並保持每位參與者的一致註冊。在市場營銷文案中,小選擇——敬稱、正式性、節奏——可能比字面忠實更重要,這些通常由風格表和地方特定規則通過提示或解碼約束注入。
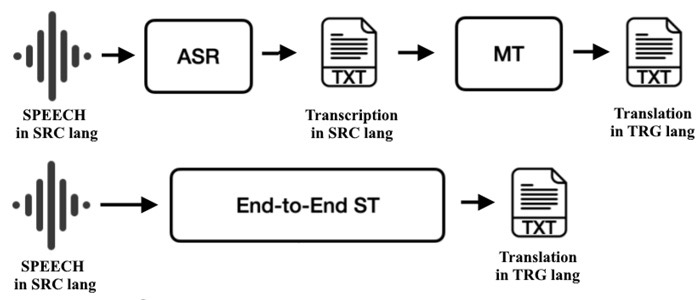
語音翻譯引入了時間和韻律。級聯系統執行 ASR → 文本 MT → TTS;每個階段都可以單獨調整,時間戳允許字幕對齊。端到端語音到文本翻譯將音頻直接映射到另一種語言的文本,減少了累積錯誤,有時能更好地保留措辭。實時場景強調延遲。系統將音頻分段為小塊,快速提供部分假設,並隨著信心增長進行修正。仔細的標點和不流暢處理改善了字幕的可讀性,並防止了指令中的歧義,因為缺少逗號可能會改變意義。
翻譯通常涉及敏感內容:用戶消息、內部文檔、健康記錄、合同。部署通過技術和程序控制作出響應。輸入和輸出在傳輸和靜止時都被加密;保留窗口被最小化;個人識別信息在處理前被掩蓋,處理後再插入。訪問控制限制誰可以查看原始內容和模型輸出。對於受監管行業,審計日誌記錄模型版本、提示、解碼參數、編輯行為和批准步驟,以重建句子如何達到發布。內容過濾器檢測風險類別,如仇恨或自我傷害;標記的段落可能需要額外的人類審查,即使語言本身看起來流暢。
術語通常是正確性與身份相遇的地方。一個產品團隊可能堅持使用“登錄”而不是“登錄”,或對保修條款的特定措辭。系統通過硬約束、軟偏見和生成後運行的驗證檢查來強制這些選擇。翻譯記憶提供精確和模糊的匹配,以便重複內容保持一致,編輯者避免重做工作。看似微不足道的地方細節——地址順序、小數分隔符、日期格式、標題大小寫——加起來會影響可信度。名稱則是特殊情況:音譯政策因市場而異,一些品牌始終保持拉丁字母,而其他品牌則被本地化。
-
生成過程中數字和代碼漂移。 複製機制和後驗證器確保產品代碼、價格和單位轉換保持不變。 - 模糊的短字符串。 添加元數據(屏幕名稱、受眾)以消歧或路由到人類;為用戶界面組件保留小型詞匯表。
- 來自通用 LLM 的過度意譯。 在風格精煉之前,使用受限解碼、術語強制和領域調整的 NMT 通過。
- 嘈雜或不對齊的訓練數據。 精心策劃語料庫,仔細對齊,並隔離引入系統性錯誤的來源。
- 忽視地方偏好。 維護每個地方的風格指南;與母語審核者測試變體;避免默默覆蓋地方規範的全球設置。
工程選擇在結果中與模型選擇一樣重要。雲 API 提供廣泛的語言覆蓋和彈性容量;自託管模型提供控制和更嚴格的數據治理;混合模式將敏感或高風險內容內部路由,並將低風險材料發送到外部。批處理提高了大批量的吞吐量;流式 API 減少了聊天和實時設置中的感知延遲。冪等鍵和重試防止重複發布。可觀察性是不可妥協的:存儲輸入和輸出的哈希標識符,將錯誤標註為類別,並顯示結合自動指標、人類分數和業務 KPI(周轉時間、每字成本、後編輯工作量)的儀表板。
為了開發者的便利性,將術語和翻譯記憶作為一流服務,提供清晰的 API,而不是分散的電子表格。建立一個內容管道,類似於任何現代數據系統:隊列、工作者、詞匯表的特徵存儲,以及每晚在靜態測試套件上運行的評估作業。為高風險領域創建門檻,根據政策禁用自動發布。當使用 LLM 時,將提示視為配置,並進行版本控制、變更日誌和回滾路徑;小的提示調整可能會以意想不到的方式改變語調。
語言技術從反映世界模式的數據中學習,包括其偏見。策劃、去重和審計減少有害的工件。在翻譯用戶生成的內容時,適當時披露機器翻譯的使用並尊重同意。數據來源很重要:團隊應該知道訓練和微調語料庫的來源、適用的許可證以及隨之而來的義務。可及性是任務的一部分:在某些情況下,可能需要使用簡單語言的變體,系統應該像尊重品牌語調一樣嚴格地遵守這些要求。
因此,AI 翻譯不是單一的模型調用,而是一個協調系統。模型學習跨語言結構;數據資產和約束引導它們;質量估計和人類編輯提供制動和轉向;隱私和審計層使過程值得信賴;儀器顯示下一步改進的地方。當這些部分設計為協同工作時,組織不僅僅是在語言之間移動單詞——它們在現代通信要求的規模上保留意圖、清晰度和身份。
AI 翻譯系統依賴於深度學習架構——特別是 Transformers——將整個句子建模為上下文表示。它們不再依賴於單詞級概率或手動定義的語法規則,而是從大型平行語料庫中學習隱含的語言結構。這使它們能夠跨領域進行概括,並比早期的基於規則或統計的系統更有效地處理口語或不合語法的輸入。
訓練數據是 AI 翻譯器能力的基礎。乾淨、特定領域且對齊良好的雙語語料庫直接影響準確性和語調。噪聲、不對齊或領域不匹配可能會將系統性錯誤傳播到輸出中。對於法律或醫療翻譯等高風險應用,策劃的數據集和經人驗證的詞匯表通常會集成到微調階段,以保持精確性和術語控制。
企業翻譯管道通常使用術語注入和翻譯記憶來保證措辭的一致性。在解碼過程中,系統可以通過受限解碼動態強制所需的術語。這些約束由語言數據庫和術語管理系統支持,這些系統根據品牌、地區和監管上下文定義批准的詞彙。持續評估工具測量引擎在更新過程中尊重這些術語的程度。
通過增量解碼、分塊音頻處理和設備內推理優化來最小化延遲。系統不再等待完整的輸入,而是生成部分假設,隨著新上下文的到來進行細化。在實時語音翻譯中,系統在響應性上以小的準確性邊際進行交易,優先考慮自然的時間和段落對齊。模型量化和硬件加速進一步減少處理延遲。
主要挑戰包括偏見傳播、數據隱私和可追溯性。訓練語料庫通常反映社會或文化偏見,這些偏見可能會在翻譯的輸出中重新出現。負責任的部署會對敏感數據進行匿名化,實施翻譯決策的審計跟蹤,並允許對高影響內容進行人類審查。數據來源的透明度和持續的偏見測試正成為合規 AI 翻譯管道的標準要求。