ゼロから手書きの PDF(01):Hello, World——最小限の利用可能な PDF を構築する

ゼロから手書きの PDF(01):Hello, World——最小限の利用可能な PDF を構築する
シリーズの目標:PDF を読み取り可能なファイル形式として理解する——まずは「動く」最小の例から始め、徐々にグラフィックス、多ページ、圧縮、リソースの再利用に拡張します。
シリーズ目次
- 第 01 篇(本文):最小の PDF を手書き(1 ページ + 1 行のテキスト)し、ツールを使って開ける標準 PDF に補完します
- 第 02 篇:コンテンツストリーム内で線を描く/矩形を描く(パス、ストローク、塗りつぶしを理解する)
- 第 03 篇:多ページ PDF(Pages ツリーの成り立ち)
- 第 04 篇:より現実世界に近づく(圧縮ストリーム、リソースの再利用、オプション構造など)
なぜ PDF の底層構造を理解する必要があるのか?
PDF(Portable Document Format、ポータブル文書形式)は、今日最も人気のあるページ記述言語の一つです。HTML/CSS のように「コンテンツと表示を分離し、再フロー可能」という考え方とは異なり、PDF はレイアウトが固定され、見たまま得られることを強調しています——どのデバイスで開いても、レイアウトは一貫しています。
PDF の底層構造を理解することにはいくつかの実際的な利点があります:
- PDF 生成の問題をデバッグする:コードライブラリを使って PDF を生成する際にエラーが発生した場合、底層構造を理解していれば問題を迅速に特定できます
- 自動化処理:テキストの一括抽出、文書の結合、透かしの追加などの操作は、構造を理解した上で正確に行うことができます
- セキュリティ監査:PDF に埋め込むことができるコンテンツ(JavaScript、添付ファイル、フォームなど)を理解することで、セキュリティ分析に役立ちます
- ファイル形式設計の学習:PDF の「オブジェクトグラフ + ランダムアクセス」設計は古典的な例であり、学ぶ価値があります
準備作業
この記事では、まず「構造は不完全だが論理的には正しい」hello-broken.pdf を作成し、その後 pdftk を使って重要な構造を自動的に補完し、hello.pdf を出力します。
- 必要なツール:pdftk(無料のコマンドラインツール、Windows/macOS/Linux に対応)
- 出力ファイル:
hello-broken.pdf(手書き)、hello.pdf(修正後に開ける)
核心概念:PDF の三層構造
PDF を理解する上で最も重要なのは、三層のメンタルモデルを構築することです:
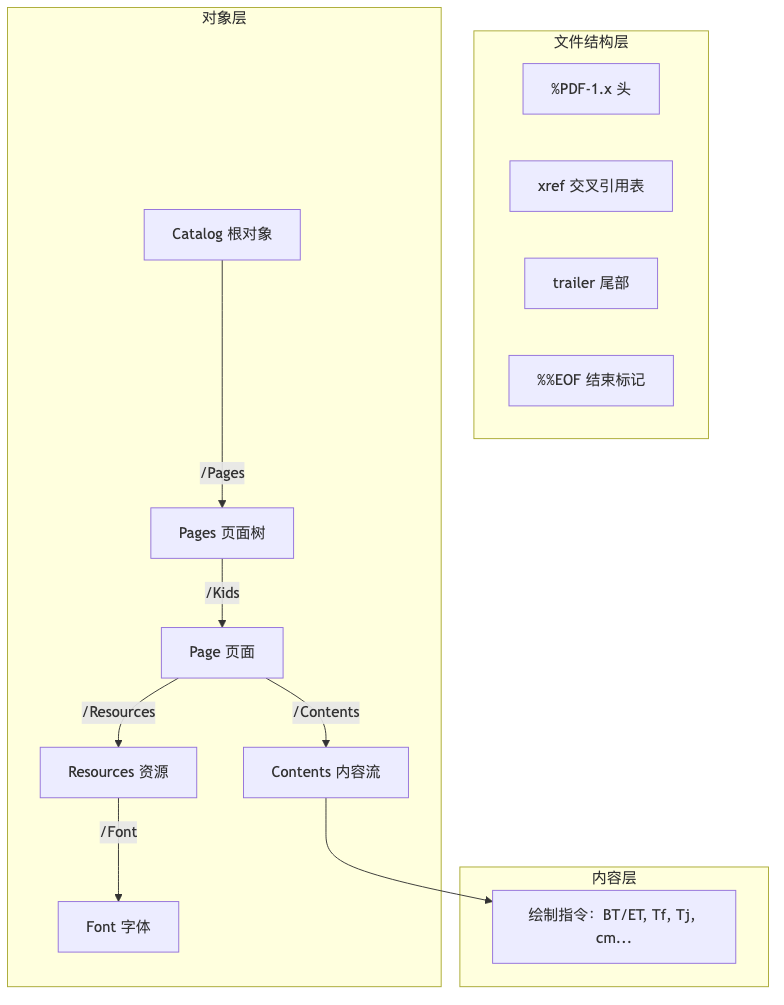
1. オブジェクト層(Document Content)
PDF 文書は多くのオブジェクトで構成されており、オブジェクト同士は間接参照(例:2 0 R)で接続されています。一般的なオブジェクトタイプ:
| タイプ | 例 | 説明 |
|---|---|---|
| Name | /Page | / で始まる名前 |
| 整数/実数 | 50、36.0 | 数値 |
| 文字列 | (Hello, World!) | 丸括弧で囲まれた文字列 |
| 配列 | [0 0 612 792] | 順序付き集合 |
| 辞書 | << /Type /Page >> | キーと値のペアの集合 |
| 間接参照 | 2 0 R | オブジェクト 2(生成番号 0)を参照 |
| ストリーム | stream...endstream | バイナリデータ(描画命令、画像など) |
2. コンテンツ層(Page Content)
実際に「テキスト/グラフィックスをページに描く」命令のシーケンスは、通常 stream ... endstream の中に書かれます。形式は:オペランドが前、オペレーターが後です。
/F0 36 Tf ← オペランド: /F0, 36 オペレーター: Tf(フォントを設定)
(Hello, World!) Tj ← オペランド: 文字列 オペレーター: Tj(テキストを描画)
3. ファイル構造層(File Structure)
リーダーが任意のオブジェクトに迅速にランダムアクセスできるようにするために、ファイルの先頭から最後まで読む必要がありません:
| 要素 | 役割 |
|---|---|
%PDF-1.x | ファイルヘッダー、PDF バージョンを識別 |
xref | クロスリファレンステーブル:オブジェクト番号 → バイトオフセット |
trailer | テール辞書:ルートオブジェクト /Root を指す |
startxref | xref テーブルの開始位置を示す |
%%EOF | ファイル終了マーク |
最小 PDF に必要なオブジェクトは?
「最小限だが文字を表示できる」PDF のオブジェクト間の参照関係は以下の通りです:
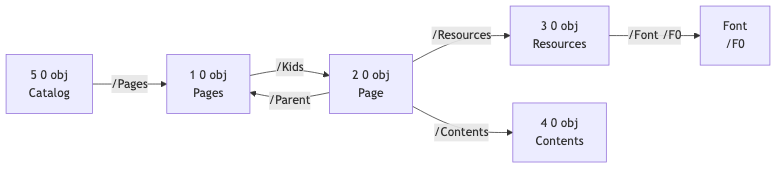
最小オブジェクトリスト:
| オブジェクト | 役割 | 重要なフィールド |
|---|---|---|
| Catalog | ルートオブジェクト、文書のエントリ | /Type /Catalog, /Pages |
| Pages | ページツリー | /Type /Pages, /Kids, /Count |
| Page | 単一ページ | /Type /Page, /MediaBox, /Resources, /Contents, /Parent |
| Resources | リソースコンテナ | /Font(フォント辞書) |
| Font | フォント定義 | /Type /Font, /BaseFont, /Subtype |
| Contents | コンテンツストリーム | 描画命令のストリーム |
実戦:手書き hello-broken.pdf
新しいファイル hello-broken.pdf を作成し、以下の内容を完全に貼り付けます:
%PDF-1.0
1 0 obj
<< /Type /Pages
/Count 1
/Kids [2 0 R]
>>
endobj
2 0 obj
<< /Type /Page
/MediaBox [0 0 612 792]
/Resources 3 0 R
/Parent 1 0 R
/Contents [4 0 R]
>>
endobj
3 0 obj
<< /Font
<< /F0
<< /Type /Font
/BaseFont /Times-Italic
/Subtype /Type1 >>
>>
>>
endobj
4 0 obj
<< >>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj
<< /Type /Catalog
/Pages 1 0 R
>>
endobj
xref
0 6
trailer
<< /Size 6
/Root 5 0 R
>>
startxref
0
%%EOF
なぜこのファイルは「壊れている」のか?
以下の内容を故意に省略または誤って記入しました:
| 欠落/誤り項目 | 説明 |
|---|---|
xref オフセット | 各オブジェクトの実際のバイトオフセットが記入されていない |
startxref | 0 と記入されており、xref の実際の位置ではない |
/Length | コンテンツストリームの長さが宣言されていない |
| バイナリマーク | ヘッダーにバイナリ識別行が欠落している |
これらはリーダーに必要な重要な情報であり、欠落すると開けないか、エラーを許容して開くことしかできません。
重要なコンテンツストリーム命令の詳細
コンテンツストリームはオブジェクト 4 0 obj の stream ... endstream の間にあり、行ごとに説明します:
1. 0. 0. 1. 50. 700. cm ← 変換行列を設定(注意:1. は浮動小数点数 1.0 を表す)
BT ← テキストオブジェクトの開始
/F0 36. Tf ← フォント F0 を選択し、フォントサイズ 36pt を設定
(Hello, World!) Tj ← 文字列を描画
ET ← テキストオブジェクトの終了
変換行列 cm オペレーター
1 0 0 1 50 700 cm は 6 要素の変換行列 [a b c d e f] に対応し、次のようになります:
| a b 0 | | 1 0 0 |
| c d 0 | = | 0 1 0 |
| e f 1 | | 50 700 1 |
a=1, b=0, c=0, d=1 の場合、これは純粋な平行移動行列であり、座標系の原点(後の描画操作の (0,0) 点)を (50, 700) に移動します。移動しない場合、デフォルトの原点はページの左下隅にあります。
テキストオペレーター
| オペレーター | 意味 | 例 |
|---|---|---|
BT | Begin Text、テキストオブジェクトの開始 | BT |
ET | End Text、テキストオブジェクトの終了 | ET |
Tf | フォントとフォントサイズを設定 | /F0 36 Tf |
Tj | 文字列を描画 | (Hello!) Tj |
pdftk を使って開ける PDF に修正する
hello-broken.pdf があるディレクトリで次のコマンドを実行します:
pdftk hello-broken.pdf output hello.pdf
任意の PDF リーダーで hello.pdf を開くと、ページ上に "Hello, World!"(Times-Italic フォント、36pt、ページの左上に位置)が表示されるはずです。
pdftk が補完したものは?
| 補完項目 | 説明 |
|---|---|
| バイナリマーク行 | %PDF-1.0 の後に印刷できない文字を追加し、バイナリファイルとして認識されるようにします |
/Length | コンテンツストリームのバイト長を計算して追加します |
xref テーブル | 各オブジェクトのバイトオフセットを計算して記入します |
startxref | xref テーブルの実際の開始位置を記入します |
なぜ xref / trailer / startxref が必要なのか?
核心目的:ランダムアクセス
500 ページの PDF を想像してみてください。xref がなければ、リーダーは 450 ページを表示するために最初から 449 ページまで解析しなければなりません——これは非常に遅いです。
xref があれば、リーダーは次のようにできます:
- まず
startxrefを読み取る → xref の位置を見つける trailerを読み取る → ルートオブジェクト/Rootを見つける- ルートオブジェクトから順にたどる → 直接 450 ページオブジェクトにジャンプ
- xref を使ってそのオブジェクトのバイトオフセットを確認 → 直接シークして読み取る
時間計算量が O(n) から O(1) に減少します。
本篇の練習
実際に hello-broken.pdf を修正し、再度 pdftk で修正して効果を観察することをお勧めします:
| 練習 | 修正内容 | 観察点 |
|---|---|---|
| A | (Hello, World!) を他の英語の短文に変更 | テキストの変化 |
| B | 36 を 12 または 72 に変更 | フォントサイズの変化 |
| C | 50 700 を 50 100 に変更 | 位置が下に移動(PDF 座標系の原点は左下) |
| D | /Times-Italic を /Helvetica または /Courier に変更 | フォントの変化 |
| E | /MediaBox [0 0 612 792] を [0 0 595 842] に変更 | 用紙が US Letter から A4 に変わる |
ヒント:PDF 座標系の原点はページの左下隅にあり、Y 軸は上向きです。
(50, 700)は左から 50pt、下から 700pt の位置を示します。
よくある質問
Q: なぜ Type1 内蔵フォントを使用するのか? TrueType ではなく?
A: Type1 の 14 種類の標準フォント(Times、Helvetica、Courier など)は PDF リーダーに必ず内蔵されており、フォントファイルを埋め込む必要がなく、最も簡単です。実際のシナリオでは、プラットフォーム間の一貫性を保証するためにフォントを埋め込む必要があります。
Q: /MediaBox [0 0 612 792] のこれらの数字は何ですか?
A: 単位はポイント(1 ポイント = 1/72 インチ)です。612 × 792 ポイント = 8.5 × 11 インチ = US Letter 用紙。A4 は 595 × 842 ポイントです。
Q: 生成番号(例:2 0 R の 0)とは何ですか?
A: 増分更新に使用されます。オブジェクトが変更されると、生成番号が 1 増加します。新しく作成された PDF では、すべてのオブジェクトの生成番号は通常 0 です。
次回予告
第 02 篇では、「手書きのコンテンツストリーム」の方法を引き続き使用し、最も基本的なグラフィックパス操作を追加します:
m(moveto)、l(lineto):パスを定義S(stroke):ストロークre(rectangle)、f(fill):矩形を描画して塗りつぶす
同じページに同時に描画できるようにします:タイトルテキスト + 水平分割線 + 矩形ボックス、「文字が書ける」から「図形が描ける」へと進化します。