AI翻訳とは?
AI翻訳とは?
目次
-
ルールから学習された表現へ - データ、信号、適応
- 生産システムの実際の動作
- 幻想なしでの品質測定
- 文脈が重要
- 音声、レイテンシ、ライブ使用
- プライバシー、セキュリティ、監査可能性
- 用語と地域のニュアンス
- 一般的な失敗モードとその軽減方法
- AI翻訳を製品に統合する
- 倫理と出所
- よくある質問
AI翻訳は、文法ルールをハードコーディングするのではなく、データから学習することによって、ある言語から別の言語への意味の自動的な変換を行います。翻訳を予測問題として扱い、ある言語のトークンのシーケンスを与えられたときに、意味、トーン、レジスタ、フォーマットを保持する別の言語のシーケンスを生成します。特異な特徴は、単に単語を生成するニューラル数学だけでなく、モデルの周りのエコシステム—データパイプライン、用語管理、品質評価、プライバシー保護、エディタのワークフロー、計測—が生の出力を信頼できる多言語コミュニケーションに変えることです。
機械翻訳アプローチの進化—ルールベースのシステムからニューラル表現へ。
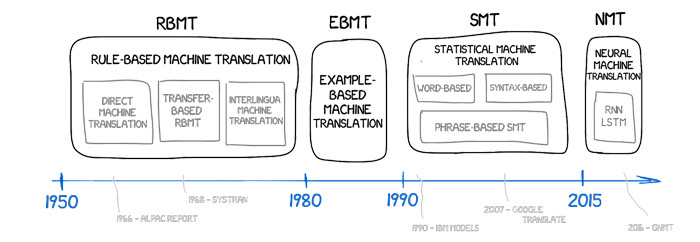
初期のシステムは、文法を手動でエンコードし、品詞やフレーズ構造を複雑なルールセットでマッピングしようとしました。統計的機械翻訳は、ルールを単語やフレーズの確率に置き換え、整列したコーパスから抽出しました。現在の標準はニューラル機械翻訳(NMT)であり、単一のネットワークがソース文を密なベクトルとして表現し、ターゲット文をトークンごとにデコードします。現代のNMTは通常、トランスフォーマーアーキテクチャに基づいています。その注意メカニズムは、モデルが全シーケンスにわたる関係を重視し、長距離依存関係や柔軟な単語順を捉えることを可能にします。語彙を管理可能に保ちながら屈折や珍しい名前をカバーするために、トークン化はバイトペアエンコーディングやSentencePieceなどのサブワードユニットに依存しています。
大規模言語モデル(LLM)はこのアプローチを拡張します。膨大な多言語コーパスで訓練され、一般的な推論のために調整されているため、彼らは多くの能力の一つとして翻訳を行うことができ、部分的な文、混合マークアップ、またはチャットサポートログのような混乱した入力を処理します。その多様性は役立ちますが、オープンエンドの生成は課題をもたらします:精度が必要な場合の言い換えや、ソースに存在しなかった詳細の自信のある主張。生産システムは、強力なNMTエンジンをLLMステージと組み合わせて、トーンを調整しながら制約付きデコードと用語注入が重要な表現を保護します。
高品質の平行コーパスは基盤です。裁判所、議会、字幕、開発者ポータル、バイリンガルウェブサイトは、監視学習のための整列した文ペアを提供します。モノリンガルテキストも重要です。バックトランスレーションを使用して、ターゲット言語の文をソースに翻訳し、追加のペアを合成し、リソースが少ない方向での流暢さとカバレッジを改善します。自己学習バリアントやノイジーチャンネルの目的は、モデルを自然なターゲット出力にさらにバイアスをかけます。
ドメイン適応は、一般的な能力がビジネス価値になる場所です。ニュースやウェブページでうまく機能する一般モデルは、法的な定型文、臨床リーフレット、特許要約では失敗する可能性があります。用語リストや翻訳メモリで強化された、ドメイン内のわずかな量の素材でのファインチューニングは、スタイルや用語を劇的にシフトさせることができます。パラメータ効率の良い技術(アダプター、LoRA)を使用すると、チームは全体のモデルを再訓練することなく、複数のドメインの個性を維持できます。時間が経つにつれて、ポストエディタの修正や評価がトレーニング信号になります:システムを組織の好ましい声に向けて動かすフィードバックループです。
実際の展開は、トークンが生成される前に始まります。コンテンツは正規化され、セグメント化され、言語が検出されます。プレースホルダーやマークアップが特定され、保存されるようにします。非常に繰り返し可能な文字列—UIラベル、製品コード、メールテンプレート—は早期に認識され、翻訳をバイパスするか、正確なバリアントに制約されます。エンジンはソースをエンコードし、ビームサーチまたは制約付きサンプリングでターゲットをデコードし、デトークン化して大文字とスペースを復元します。ポストプロセッシングはタグ、数字、固有名詞を再挿入します。品質評価モデルは信頼度を予測し、低信頼度のセグメントを人間のエディタにルーティングし、高信頼度のものはレイテンシが重要な場合に公開を許可します。
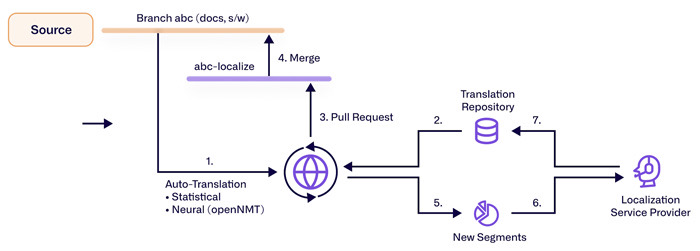
いくつかのレバーが翻訳の特性を定義します:
- 制約付きデコード:必要な用語は出現しなければならず、形態的に豊かな言語に対して屈折の柔軟性があります。
- 用語注入とメモリ:好ましいバリアントや以前に承認された文が出力を一貫性に導きます。
- リスクルーティング:品質評価が自動公開とポストエディットの閾値を設定し、コスト、速度、精度のバランスを取ります。
コンピュータ支援翻訳ツールは、エディタのコックピットを提供します。提案は入力中に更新され、差分はポストエディットの労力を測定し、キーストロークと時間のメトリクスはモデルが苦労している場所を示します。これらの痕跡はトレーニングデータの選択とモデルの更新に役立ちます。計測は不可欠です:レイテンシ、スループット、エラータイプ、エディタの労力は地域とドメインによって追跡されます。チームはダッシュボードメトリクスから回帰を引き起こした正確な文に掘り下げることができます。
自動メトリクスは迅速なフィードバックを提供します。BLEUやchrFはn-gramの重複や文字レベルの類似性を測定します。COMETのような学習メトリクスは、出力と参照をニューラルエンコーダーを通じて比較することで人間の判断とより良く相関します。参照なしの品質評価は、ソースと仮説のみを使用してスコアやエラー範囲を予測し、リアルタイムのルーティングを可能にします。しかし、これらのどれも人間のレビューに取って代わるものではありません。言語学者は適合性(意味が保持されているか)と流暢さ(自然さ)を確認し、ドメイン固有のチェックリストを適用します:出力はブランドの声、法的な表現、禁忌の表現、名前、住所、小数点の地域の慣習を尊重していますか?良いプログラムは、自動ダッシュボードと定期的な盲目的な人間の評価を組み合わせ、長距離の合意、イディオム、コード混合スラングなどの難しい現象を種にします。
多くの翻訳エラーは文脈の失敗です。代名詞、省略、談話リンクは文を超えた認識を必要とします。文書レベルのモデルは周囲の文に条件付けされ、検索強化翻訳は文書の早い段階から関連するセグメントを取得し、デコード中にそれらに注意を払います。サポートチャットでは、インクリメンタルデコードが話者のターンを尊重し、参加者ごとに一貫したレジスタを維持します。マーケティングコピーでは、小さな選択—敬称、形式、リズム—が文字通りの忠実度よりも重要になることがあり、これらはしばしばスタイルシートや地域特有のルールによってプロンプトやデコード制約に注入されます。
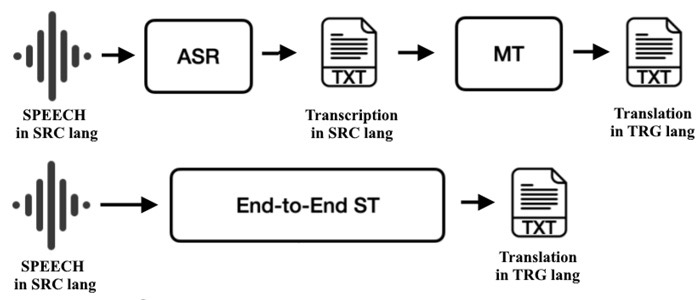
音声翻訳はタイミングとプロソディを導入します。カスケードシステムはASR → テキストMT → TTSを実行します。各ステージは別々に調整でき、タイムスタンプは字幕の整列を可能にします。エンドツーエンドの音声からテキストへの翻訳は、音声を直接別の言語のテキストにマッピングし、累積エラーを減らし、時にはフレーズをより良く保持します。ライブシナリオでは、レイテンシが強調されます。システムは音声を小さなチャンクに分割し、部分的な仮説を迅速に提供し、自信が高まるにつれてそれらを修正します。慎重な句読点と不流暢さの処理は、キャプションの可読性を向上させ、欠落したコンマが意味を変える可能性のある指示の曖昧さを防ぎます。
翻訳はしばしば敏感なコンテンツに触れます:ユーザーメッセージ、内部文書、健康記録、契約。展開は技術的および手続き的な制御に応じます。入力と出力は、転送中および静止中に暗号化され、保持期間は最小限に抑えられます。個人を特定できる情報は処理前にマスクされ、処理後に再挿入されます。アクセス制御は、生のコンテンツやモデル出力を表示できる人を制限します。規制された業界では、監査ログがモデルのバージョン、プロンプト、デコードパラメータ、エディタのアクション、承認ステップを記録し、文が公開に至るまでの過程を再構築します。コンテンツフィルターは、ヘイトや自傷などのリスクのあるカテゴリを検出します。フラグが付けられた部分は、言語自体が流暢に見える場合でも、追加の人間のレビュアーを必要とすることがあります。
用語は、正確さがアイデンティティに出会う場所です。製品チームは「サインイン」ではなく「ログイン」を主張するか、保証条項の特定の表現を主張するかもしれません。システムは、生成後に実行されるハード制約、ソフトバイアス、検証チェックを通じてこれらの選択を強制します。翻訳メモリは、正確な一致とあいまいな一致を提供し、繰り返しのコンテンツが一貫性を保ち、エディタが作業をやり直さないようにします。住所の順序、小数点の区切り、日付形式、タイトルの大文字化など、些細に見える地域の詳細が信頼性を高めます。名前は特別なケースを示します:音訳ポリシーは市場によって異なり、一部のブランドは常にラテン文字で保持され、他のブランドはローカライズされます。
-
生成中に数値やコードがずれる。 コピー機構とポストバリデーターは、製品コード、価格、単位換算がそのまま保持されることを保証します。 - あいまいな短い文字列。 メタデータ(画面名、オーディエンス)を追加してあいまいさを解消するか、人間にルーティングします。UIコンポーネントのためのミニ用語集を保持します。
- 一般的なLLMからの過剰な言い換え。 制約付きデコード、用語の強制、スタイルの洗練の前にドメイン調整されたNMTパスを使用します。
- ノイズの多いまたは不整合なトレーニングデータ。 コーパスをキュレーションし、慎重に整列させ、体系的なエラーを引き起こすソースを隔離します。
- 地域の好みを無視する。 地域ごとのスタイルガイドを維持し、ネイティブレビュアーでバリアントをテストし、ローカルの規範を静かに上書きするグローバル設定を避けます。
エンジニアリングの選択は、結果をモデルの選択と同じくらい形作ります。クラウドAPIは広範な言語カバレッジと弾力的なキャパシティを提供し、自己ホスト型モデルは制御とデータガバナンスを提供します。ハイブリッドは、敏感または高リスクのコンテンツを内部でルーティングし、低リスクの素材を外部に送信します。バッチ処理は大規模なドロップのスループットを改善し、ストリーミングAPIはチャットやライブ設定でのレイテンシを減少させます。冪等性キーと再試行は重複した公開から保護します。可視性は交渉の余地がありません:入力と出力のハッシュ化された識別子を保存し、エラーをカテゴリで注釈し、自動メトリクス、人間のスコア、ビジネスKPI(ターンアラウンドタイム、単語あたりのコスト、ポストエディットの労力)を組み合わせたダッシュボードを表示します。
開発者の使いやすさのために、用語と翻訳メモリを明確なAPIを持つファーストクラスのサービスにし、散在するスプレッドシートではなくします。現代のデータシステムのように見えるコンテンツパイプラインを構築します:キュー、ワーカー、用語集のためのフィーチャーストア、静的テストスイートで毎晩実行される評価ジョブ。自動公開がポリシーによって無効化される高リスクドメインのためのゲートを作成します。そして、LLMを使用する際には、プロンプトを構成として扱い、バージョン管理、変更ログ、ロールバックパスを持たせます。小さなプロンプトの調整が予期しない方法でトーンを変える可能性があります。
言語技術は、世界のパターンを反映したデータから学び、その中にはバイアスも含まれます。キュレーション、重複排除、監査は有害なアーティファクトを減少させます。ユーザー生成コンテンツを翻訳する際には、適切な場合に機械翻訳の使用を開示し、同意を尊重します。データの出所は重要です:チームは、トレーニングおよびファインチューニングコーパスがどこから来たのか、どのライセンスが適用されるのか、どのような義務が続くのかを知っておくべきです。アクセシビリティも任務の一部です:平易な言語のバリアントが必要な場合があり、システムはそれらの要件をブランドトーンと同じくらい厳密に尊重するべきです。
したがって、AI翻訳は単一のモデル呼び出しではなく、調整されたシステムです。モデルはクロスリンガル構造を学び、データ資産と制約がそれらを導き、品質評価と人間のエディタがブレーキとステアリングを提供し、プライバシーと監査のレイヤーがプロセスを信頼できるものにします。計測は次に改善すべき場所を示します。これらの要素が協力して機能するように設計されていると、組織は単に言葉を言語間で移動させるのではなく、製品、市場、メディア全体で意図、明確さ、アイデンティティを保持します。
AI翻訳システムは、特にトランスフォーマーを使用した深層学習アーキテクチャに依存して、文全体を文脈的表現としてモデル化します。単語レベルの確率や手動で定義された文法ルールに依存するのではなく、大規模な平行コーパスから暗黙の言語構造を学びます。これにより、ドメインを超えて一般化し、従来のルールベースまたは統計的システムよりも口語的または文法的に不正確な入力をより効果的に処理できます。
トレーニングデータは、AI翻訳者の能力の基盤です。クリーンでドメイン特有の、よく整列されたバイリンガルコーパスは、精度とトーンに直接影響します。ノイズ、不整合、またはドメインの不一致は、出力に体系的なエラーを引き起こす可能性があります。法的または医療翻訳などの高リスクのアプリケーションでは、キュレーションされたデータセットや人間によって検証された用語集がファインチューニング段階に統合され、精度と用語管理を維持します。
エンタープライズ翻訳パイプラインは、通常、用語注入と翻訳メモリを使用して一貫した表現を保証します。デコード中に、システムは制約付きデコードを通じて必要な用語を動的に強制できます。これらの制約は、ブランド、地域、規制の文脈によって承認された語彙を定義する言語データベースや用語管理システムによって支えられています。継続的な評価ツールは、エンジンが更新を通じてそれらの用語をどれだけ一貫して尊重しているかを測定します。
レイテンシは、インクリメンタルデコード、チャンク化された音声処理、デバイス上の推論最適化を通じて最小化されます。完全な入力を待つのではなく、ストリーミングモデルは新しいコンテキストが到着するにつれて洗練される部分的な仮説を生成します。ライブ音声翻訳では、システムは応答性を優先し、自然なタイミングとセグメントの整列を重視します。モデルの量子化とハードウェアアクセラレーションは、処理の遅延をさらに減少させます。
主要な課題には、バイアスの伝播、データプライバシー、トレーサビリティが含まれます。トレーニングコーパスは、翻訳された出力に再現される可能性のある社会的または文化的バイアスを反映することがよくあります。責任ある展開は、敏感なデータを匿名化し、翻訳の決定に対する監査トレイルを実装し、高影響のコンテンツに対して人間のレビューを許可します。データの出所の透明性と継続的なバイアステストは、コンプライアントなAI翻訳パイプラインの標準要件となりつつあります。