Che cos'è la traduzione AI?
Che cos'è la traduzione AI?
Indice
-
Dalle regole alle rappresentazioni apprese - Dati, segnali e adattamento
- Come funzionano realmente i sistemi di produzione
- Misurare la qualità senza illusioni
- Il contesto è re
- Parlato, latenza e utilizzo dal vivo
- Privacy, sicurezza e auditabilità
- Terminologia e sfumature locali
- Modalità di fallimento comuni—e come i team le mitigano
- Integrare la traduzione AI nei prodotti
- Etica e provenienza
- FAQs
La traduzione AI è la resa automatizzata del significato da una lingua all'altra apprendendo dai dati piuttosto che codificando a mano le regole grammaticali. Tratta la traduzione come un problema di previsione: data una sequenza di token in una lingua, produce una sequenza nell'altra che preserva senso, tono, registro e formattazione. La caratteristica distintiva non è solo la matematica neurale che genera parole; è l'ecosistema attorno ai modelli—pipeline di dati, controllo della terminologia, stima della qualità, protezioni della privacy, flussi di lavoro degli editor e strumentazione—che trasforma le uscite grezze in comunicazione multilingue affidabile.
Dalle regole alle rappresentazioni apprese
Evoluzione degli approcci alla traduzione automatica—da sistemi basati su regole a rappresentazioni neurali.
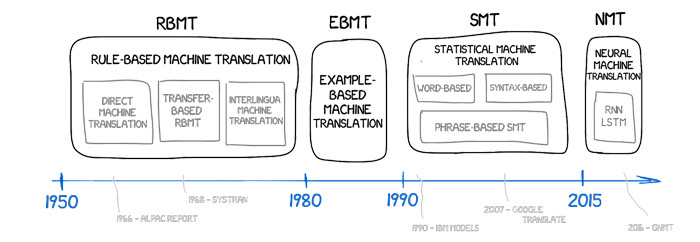
I primi sistemi tentavano di codificare le grammatiche a mano, mappando le parti del discorso e le strutture frasali con elaborati set di regole. La traduzione automatica statistica ha sostituito le regole con probabilità su parole e frasi estratte da corpora allineati. Lo standard attuale è la traduzione automatica neurale (NMT), in cui una singola rete impara a rappresentare la frase sorgente come vettori densi e a decodificare una frase target token per token. La moderna NMT è solitamente costruita sull'architettura Transformer. Il suo meccanismo di attenzione consente al modello di pesare le relazioni attraverso l'intera sequenza, catturando dipendenze a lungo raggio e un ordine delle parole flessibile. Per mantenere i vocabolari gestibili pur coprendo inflessioni e nomi rari, la tokenizzazione si basa su unità subword come Byte-Pair Encoding o SentencePiece.
I modelli di linguaggio di grandi dimensioni (LLM) estendono questo approccio. Addestrati su enormi corpora multilingue e sintonizzati per il ragionamento generale, possono tradurre come una delle molte capacità, gestendo input disordinati come frasi parziali, markup misti o registri di supporto chiacchierati. La loro versatilità è utile, ma la generazione aperta porta a sfide: parafrasi dove è richiesta precisione, o affermazioni sicure di dettagli che non erano mai presenti nella sorgente. I sistemi di produzione spesso abbinano un potente motore NMT con una fase LLM che regola il tono mentre la decodifica vincolata e l'iniezione di termini proteggono la formulazione critica.
I corpora paralleli di alta qualità sono la spina dorsale. Tribunali, parlamenti, sottotitoli, portali per sviluppatori e siti web bilingue forniscono coppie di frasi allineate per l'apprendimento supervisionato. Anche il testo monolingue è importante. Con la retro-traduzione, le frasi nella lingua target vengono tradotte nella sorgente per sintetizzare coppie aggiuntive, migliorando la fluidità e la copertura in direzioni a bassa risorsa. Le varianti di auto-addestramento e gli obiettivi di canale rumoroso inclinano ulteriormente i modelli verso un output target naturale.
L'adattamento di dominio è dove la competenza generica diventa valore commerciale. Un modello generale che funziona bene su notizie e pagine web può vacillare su boilerplate legali, opuscoli clinici o abstract di brevetti. Il fine-tuning su anche modesti quantitativi di materiale in dominio—augmentato da liste di terminologia e memorie di traduzione—può cambiare drasticamente stile e terminologia. Tecniche efficienti in termini di parametri (adattatori, LoRA) consentono ai team di mantenere più personalità di dominio senza riaddestrare l'intero modello. Nel tempo, le correzioni e le valutazioni post-editor diventano segnali di addestramento: cicli di feedback che spostano il sistema verso la voce preferita di un'organizzazione.
Come funzionano realmente i sistemi di produzione
Le implementazioni reali iniziano prima che venga generato qualsiasi token. I contenuti vengono normalizzati, segmentati e rilevati per lingua; i segnaposto e il markup vengono identificati in modo che possano essere preservati. Le stringhe altamente ripetibili—etichette UI, codici prodotto, modelli di email—vengono riconosciute precocemente e spesso bypassano la traduzione o sono vincolate a varianti esatte. Il motore codifica la sorgente, decodifica il target con ricerca a fascio o campionamento vincolato e detokenizza per ripristinare maiuscole e spaziatura. Il post-processing reinserisce tag, numeri ed entità nominate. Un modello di stima della qualità prevede la fiducia, instradando segmenti a bassa fiducia verso editor umani mentre consente a quelli ad alta fiducia di pubblicare quando la latenza è importante.
Alcuni leve definiscono le caratteristiche della traduzione:
- Decodifica vincolata: i termini richiesti devono apparire, con flessibilità inflessionale per lingue morfologicamente ricche.
- Iniezione di termini e memorie: varianti preferite e frasi precedentemente approvate orientano le uscite verso la coerenza.
- Instradamento del rischio: la stima della qualità stabilisce soglie per auto-pubblicazione vs. post-editing, bilanciando costo, velocità e accuratezza.
Gli strumenti di traduzione assistita da computer forniscono il cockpit per gli editor. I suggerimenti si aggiornano mentre digitano; le differenze misurano lo sforzo di post-editing; le metriche di battitura e tempo mostrano dove i modelli faticano. Queste tracce informano la selezione dei dati di addestramento e gli aggiornamenti del modello. L'istrumentazione è essenziale: latenza, throughput, tipi di errore e sforzo dell'editor vengono tracciati per locale e dominio. I team possono approfondire da una metrica del dashboard alla frase esatta che ha causato una regressione.
Misurare la qualità senza illusioni
Le metriche automatiche forniscono feedback rapidi. BLEU e chrF misurano la sovrapposizione n-gram o la similarità a livello di carattere; metriche apprese come COMET correlano meglio con i giudizi umani confrontando uscite e riferimenti attraverso codificatori neurali. La stima della qualità senza riferimento prevede un punteggio e persino intervalli di errore utilizzando solo la sorgente e l'ipotesi, abilitando l'instradamento in tempo reale. Eppure nessuna di queste sostituisce la revisione umana. I linguisti controllano l'adeguatezza (significato preservato) e la fluidità (naturalità), e applicano liste di controllo specifiche per il dominio: l'output rispetta la voce del marchio, la formulazione legale, la terminologia di controindicazione e le convenzioni locali per nomi, indirizzi e decimali? Buoni programmi mescolano dashboard automatizzati con valutazioni umane periodiche, seminate con fenomeni difficili come l'accordo a lungo raggio, le espressioni idiomatiche e il gergo misto.
Molti errori di traduzione sono fallimenti di contesto. Pronomi, ellissi e collegamenti discorsivi richiedono consapevolezza oltre la frase. I modelli a livello di documento si condizionano sulle frasi circostanti; la traduzione aumentata da recupero estrae segmenti rilevanti da precedenti nel documento, guide di stile o storie di ticket e vi presta attenzione durante la decodifica. Nella chat di supporto, la decodifica incrementale rispetta i turni di parola e mantiene un registro coerente per partecipante. Nel testo di marketing, piccole scelte—onorifici, formalità, ritmo—possono contare più della fedeltà letterale, e queste sono spesso governate da fogli di stile e regole specifiche per locale iniettate nei prompt o nei vincoli di decodifica.
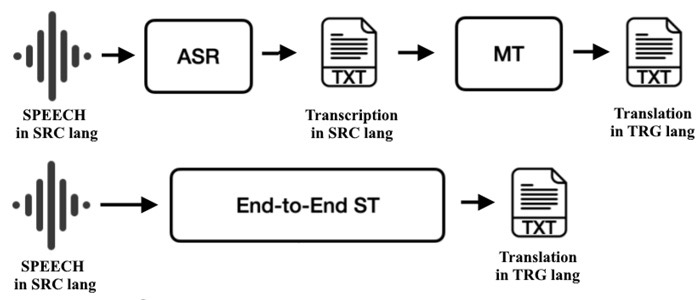
Parlato, latenza e utilizzo dal vivo
La traduzione del parlato introduce tempistiche e prosodia. I sistemi a cascata eseguono ASR → MT di testo → TTS; ogni fase può essere sintonizzata separatamente, e i timestamp consentono l'allineamento dei sottotitoli. La traduzione vocale end-to-end mappa l'audio direttamente nel testo di un'altra lingua, riducendo gli errori composti e talvolta preservando meglio la formulazione. Gli scenari dal vivo enfatizzano la latenza. I sistemi segmentano l'audio in piccoli pezzi, forniscono ipotesi parziali rapidamente e le revisionano man mano che la fiducia cresce. Una punteggiatura attenta e una gestione delle disfluenze migliorano la leggibilità nei sottotitoli e prevengono ambiguità nelle istruzioni dove una virgola mancante può cambiare il significato.
Privacy, sicurezza e auditabilità
La traduzione spesso tocca contenuti sensibili: messaggi degli utenti, documenti interni, cartelle cliniche, contratti. Le implementazioni rispondono con controlli tecnici e procedurali. Gli input e gli output sono crittografati in transito e a riposo; le finestre di retention sono minimizzate; le informazioni personali identificabili sono mascherate prima dell'elaborazione e reinserite dopo. I controlli di accesso limitano chi può visualizzare contenuti grezzi e output del modello. Per le industrie regolamentate, i registri di audit registrano versioni del modello, prompt, parametri di decodifica, azioni degli editor e passaggi di approvazione per ricostruire come una frase è arrivata alla pubblicazione. I filtri di contenuto rilevano categorie rischiose come odio o autolesionismo; i passaggi segnalati possono richiedere un ulteriore revisore umano anche se la lingua stessa appare fluente.
Terminologia e sfumature locali
La terminologia è spesso dove la correttezza incontra l'identità. Un team di prodotto potrebbe insistere su “Accedi” piuttosto che “Login”, o su una formulazione specifica per una clausola di garanzia. Il sistema applica queste scelte attraverso vincoli rigidi, bias morbidi e controlli di validazione che vengono eseguiti dopo la generazione. Le memorie di traduzione forniscono corrispondenze esatte e fuzzy in modo che i contenuti ripetuti rimangano coerenti e gli editor evitino di rifare il lavoro. I dettagli locali che sembrano minori—ordine degli indirizzi, separatori decimali, formati di data, capitalizzazione dei titoli—si sommano a credibilità. I nomi presentano casi speciali: le politiche di traslitterazione differiscono per mercato, e alcuni marchi sono sempre mantenuti in caratteri latini mentre altri sono localizzati.
Modalità di fallimento comuni—e come i team le mitigano
-
Numeri e codici che si spostano durante la generazione. I meccanismi di copia e i post-validator garantiscono che i codici prodotto, i prezzi e le conversioni di unità rimangano intatti. - Stringhe brevi ambigue. Aggiungi metadati (nome dello schermo, pubblico) per disambiguare o instradare a umani; mantieni mini-glossari per componenti UI.
- Parafrasi eccessiva da LLM generali. Usa decodifica vincolata, enforcement di termini e un passaggio NMT sintonizzato per il dominio prima del raffinamento stilistico.
- Dati di addestramento rumorosi o disallineati. Cura i corpora, allinea con attenzione e quarantena le fonti che introducono errori sistematici.
- Negligenza delle preferenze locali. Mantieni guide di stile per ogni locale; testa varianti con revisori nativi; evita impostazioni globali che sovrascrivono silenziosamente le norme locali.
Integrare la traduzione AI nei prodotti
Le scelte ingegneristiche plasmano i risultati tanto quanto la scelta del modello. Le API cloud offrono una copertura linguistica ampia e capacità elastica; i modelli auto-ospitati forniscono controllo e governance dei dati più rigorosa; gli ibridi instradano contenuti sensibili o ad alto rischio internamente e inviano materiale a basso rischio all'esterno. L'elaborazione in batch migliora il throughput per grandi quantità; le API in streaming riducono la latenza percepita in chat e impostazioni dal vivo. Le chiavi di idempotenza e i retry proteggono contro la pubblicazione duplicata. L'osservabilità è non negoziabile: memorizza identificatori hashati per input e output, annota gli errori con categorie e mostra dashboard che combinano metriche automatiche, punteggi umani e KPI aziendali (tempo di risposta, costo per parola, sforzo di post-editing).
Per l'ergonomia degli sviluppatori, rendi la terminologia e la memoria di traduzione servizi di prima classe con API chiare piuttosto che fogli di calcolo sparsi. Costruisci una pipeline di contenuti che assomigli a qualsiasi sistema di dati moderno: code, lavoratori, feature store per glossari e lavori di valutazione che vengono eseguiti ogni notte su suite di test statiche. Crea porte per domini ad alto rischio dove la pubblicazione automatica è disabilitata per policy. E quando usi LLM, tratta i prompt come configurazione con versioning, registri delle modifiche e percorsi di rollback; una piccola modifica al prompt può cambiare il tono in modi inaspettati.
Le tecnologie linguistiche apprendono da dati che riflettono i modelli del mondo, comprese le sue distorsioni. La cura, la deduplicazione e l'audit riducono artefatti dannosi. Quando si traducono contenuti generati dagli utenti, divulgare l'uso della traduzione automatica dove appropriato e rispettare il consenso. La provenienza dei dati è importante: i team dovrebbero sapere da dove provengono i corpora di addestramento e fine-tuning, quali licenze si applicano e quali obblighi seguono. L'accessibilità è parte del mandato: varianti in linguaggio semplice possono essere necessarie in alcuni contesti, e i sistemi dovrebbero onorare tali requisiti con la stessa rigidità con cui onorano il tono del marchio.
La traduzione AI, quindi, non è una singola chiamata al modello ma un sistema coordinato. I modelli apprendono la struttura cross-linguale; gli asset e i vincoli dei dati li guidano; la stima della qualità e gli editor umani forniscono freni e sterzo; i livelli di privacy e audit rendono il processo affidabile; l'istrumentazione mostra dove migliorare successivamente. Quando questi pezzi sono progettati per lavorare insieme, le organizzazioni non si limitano a spostare parole tra lingue—preservano l'intento, la chiarezza e l'identità attraverso prodotti, mercati e mezzi su scala che la comunicazione moderna richiede.
I sistemi di traduzione AI si basano su architetture di deep learning—specialmente i Transformer—per modellare intere frasi come rappresentazioni contestuali. Invece di fare affidamento su probabilità a livello di parola o regole grammaticali definite manualmente, apprendono strutture linguistiche implicite da grandi corpora paralleli. Questo consente loro di generalizzare attraverso i domini e gestire input colloquiali o non grammaticali in modo più efficace rispetto ai precedenti sistemi basati su regole o statistici.
I dati di addestramento sono la base della capacità di un traduttore AI. Corpora bilingue puliti, specifici per dominio e ben allineati influenzano direttamente l'accuratezza e il tono. Rumore, disallineamenti o mismatch di dominio possono propagare errori sistematici nell'output. Per applicazioni ad alto rischio come la traduzione legale o medica, set di dati curati e glossari validati da umani sono spesso integrati nelle fasi di fine-tuning per mantenere precisione e controllo della terminologia.
Le pipeline di traduzione aziendale utilizzano tipicamente iniezione di termini e memorie di traduzione per garantire frasi coerenti. Durante la decodifica, il sistema può applicare dinamicamente i termini richiesti attraverso la decodifica vincolata. Questi vincoli sono supportati da database linguistici e sistemi di gestione della terminologia che definiscono il vocabolario approvato per marchio, locale e contesto normativo. Gli strumenti di valutazione continua misurano quanto costantemente il motore rispetta quei termini attraverso gli aggiornamenti.
La latenza è minimizzata attraverso la decodifica incrementale, l'elaborazione audio a chunk e le ottimizzazioni di inferenza su dispositivo. Invece di attendere input completi, i modelli in streaming generano ipotesi parziali che si affinano man mano che arriva nuovo contesto. Nella traduzione vocale dal vivo, i sistemi scambiano un piccolo margine di accuratezza per reattività, dando priorità al tempismo naturale e all'allineamento dei segmenti. La quantizzazione del modello e l'accelerazione hardware riducono ulteriormente i ritardi di elaborazione.
Le sfide chiave includono la propagazione dei bias, la privacy dei dati e la tracciabilità. I corpora di addestramento riflettono spesso bias sociali o culturali che possono riapparire nell'output tradotto. I deploy responsabili anonimizzano i dati sensibili, implementano registri di audit per le decisioni di traduzione e consentono la revisione umana di contenuti ad alto impatto. La trasparenza nella provenienza dei dati e il continuo testing dei bias stanno diventando requisiti standard per le pipeline di traduzione AI conformi.