Apa Itu Terjemahan AI?
Apa Itu Terjemahan AI?
Daftar Isi
-
Dari aturan ke representasi yang dipelajari - Data, sinyal, dan adaptasi
- Bagaimana sistem produksi sebenarnya bekerja
- Mengukur kualitas tanpa ilusi
- Konteks adalah raja
- Ucapan, latensi, dan penggunaan langsung
- Privasi, keamanan, dan auditabilitas
- Terminologi dan nuansa lokal
- Mode kegagalan umum—dan bagaimana tim menguranginya
- Mengintegrasikan terjemahan AI ke dalam produk
- Etika dan asal-usul
- FAQs
Terjemahan AI adalah penggambaran otomatis makna dari satu bahasa ke bahasa lain dengan belajar dari data daripada mengkodekan aturan tata bahasa secara keras. Ini memperlakukan terjemahan sebagai masalah prediksi: diberikan urutan token dalam satu bahasa, menghasilkan urutan dalam bahasa lain yang mempertahankan makna, nada, register, dan format. Ciri khasnya bukan hanya matematika saraf yang menghasilkan kata-kata; ini adalah ekosistem di sekitar model—saluran data, kontrol terminologi, estimasi kualitas, perlindungan privasi, alur kerja editor, dan instrumentasi—yang mengubah output mentah menjadi komunikasi multibahasa yang dapat diandalkan.
Dari aturan ke representasi yang dipelajari
Evolusi pendekatan terjemahan mesin—dari sistem berbasis aturan ke representasi neural.
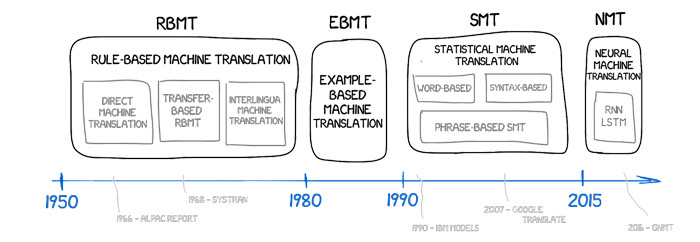
Sistem awal mencoba untuk mengkodekan tata bahasa secara manual, memetakan bagian-bagian ucapan dan struktur frasa dengan seperangkat aturan yang rumit. Terjemahan mesin statistik menggantikan aturan dengan probabilitas atas kata-kata dan frasa yang diekstrak dari korpus yang diselaraskan. Standar saat ini adalah terjemahan mesin neural (NMT), di mana satu jaringan belajar untuk merepresentasikan kalimat sumber sebagai vektor padat dan untuk mendekode kalimat target token demi token. NMT modern biasanya dibangun di atas arsitektur Transformer. Mekanisme perhatiannya memungkinkan model untuk menimbang hubungan di seluruh urutan, menangkap ketergantungan jarak jauh dan urutan kata yang fleksibel. Untuk menjaga kosakata tetap dapat dikelola sambil mencakup infleksi dan nama-nama langka, tokenisasi bergantung pada unit sub-kata seperti Byte-Pair Encoding atau SentencePiece.
Model bahasa besar (LLM) memperluas pendekatan ini. Dilatih pada korpus multibahasa yang besar dan disesuaikan untuk penalaran umum, mereka dapat menerjemahkan sebagai salah satu kemampuan di antara banyak, menangani input yang berantakan seperti kalimat parsial, markup campuran, atau log dukungan yang panjang. Versatilitas mereka sangat membantu, tetapi generasi terbuka membawa tantangan: parafrase di mana presisi diperlukan, atau pernyataan percaya diri tentang detail yang tidak pernah ada dalam sumber. Sistem produksi sering kali memasangkan mesin NMT yang kuat dengan tahap LLM yang menyesuaikan nada sementara decoding yang dibatasi dan injeksi istilah melindungi wording yang kritis.
Korpus paralel berkualitas tinggi adalah tulang punggungnya. Pengadilan, parlemen, subtitle, portal pengembang, dan situs web dwibahasa menyediakan pasangan kalimat yang diselaraskan untuk pembelajaran terawasi. Teks monolingual juga penting. Dengan back-translation, kalimat dalam bahasa target diterjemahkan ke dalam sumber untuk mensintesis pasangan tambahan, meningkatkan kelancaran dan cakupan dalam arah sumber daya rendah. Variasi pelatihan mandiri dan tujuan saluran bising lebih lanjut membiasakan model menuju output target yang alami.
Adaptasi domain adalah di mana kompetensi umum menjadi nilai bisnis. Model umum yang berkinerja baik pada berita dan halaman web dapat terhambat pada boilerplate hukum, leaflet klinis, atau abstrak paten. Penyesuaian pada bahkan jumlah bahan dalam domain yang moderat—dilengkapi dengan daftar terminologi dan memori terjemahan—dapat mengubah gaya dan terminologi secara dramatis. Teknik yang efisien dalam parameter (adapters, LoRA) memungkinkan tim untuk mempertahankan beberapa kepribadian domain tanpa melatih ulang seluruh model. Seiring waktu, koreksi dan penilaian pasca-editor menjadi sinyal pelatihan: umpan balik yang menggerakkan sistem menuju suara yang diinginkan organisasi.
Bagaimana sistem produksi sebenarnya bekerja
Penerapan nyata dimulai sebelum token apa pun dihasilkan. Konten dinormalisasi, disegmentasi, dan terdeteksi bahasanya; placeholder dan markup diidentifikasi agar dapat dipertahankan. String yang sangat dapat diulang—label UI, kode produk, template email—diakui lebih awal dan sering kali melewati terjemahan atau dibatasi pada varian yang tepat. Mesin mengkodekan sumber, mendekode target dengan pencarian beam atau sampling yang dibatasi, dan detokenisasi untuk mengembalikan casing dan spasi. Pemrosesan pasca-menyisipkan kembali tag, angka, dan entitas bernama. Model estimasi kualitas memprediksi kepercayaan, mengarahkan segmen dengan kepercayaan rendah kepada editor manusia sementara yang memiliki kepercayaan tinggi dapat diterbitkan saat latensi penting.
Beberapa pengungkit mendefinisikan karakteristik terjemahan:
- Dekoding yang dibatasi: istilah yang diperlukan harus muncul, dengan fleksibilitas infleksi untuk bahasa yang kaya morfologi.
- Injeksi istilah dan memori: varian yang disukai dan kalimat yang telah disetujui sebelumnya mengarahkan output menuju konsistensi.
- Pengarahan risiko: estimasi kualitas menetapkan ambang batas untuk publikasi otomatis vs. pasca-edit, menyeimbangkan biaya, kecepatan, dan akurasi.
Alat terjemahan yang dibantu komputer menyediakan kokpit untuk editor. Saran diperbarui saat mereka mengetik; perbedaan mengukur upaya pasca-editing; metrik ketukan dan waktu menunjukkan di mana model mengalami kesulitan. Jejak ini menginformasikan pemilihan data pelatihan dan pembaruan model. Instrumentasi sangat penting: latensi, throughput, jenis kesalahan, dan upaya editor dilacak berdasarkan lokal dan domain. Tim dapat menggali dari metrik dasbor ke kalimat tepat yang menyebabkan regresi.
Metrik otomatis memberikan umpan balik cepat. BLEU dan chrF mengukur tumpang tindih n-gram atau kesamaan tingkat karakter; metrik yang dipelajari seperti COMET lebih berkorelasi dengan penilaian manusia dengan membandingkan output dan referensi melalui pengkode neural. Estimasi kualitas tanpa referensi memprediksi skor dan bahkan rentang kesalahan hanya menggunakan sumber dan hipotesis, memungkinkan pengalihan waktu nyata. Namun tidak ada dari ini yang menggantikan tinjauan manusia. Ahli bahasa memeriksa kecukupan (makna yang dipertahankan) dan kelancaran (kealamian), dan mereka menerapkan daftar periksa spesifik domain: apakah output menghormati suara merek, frasa hukum, wording kontraindikasi, dan konvensi lokal untuk nama, alamat, dan desimal? Program yang baik mencampur dasbor otomatis dengan evaluasi manusia buta berkala, yang ditanam dengan fenomena sulit seperti kesepakatan jarak jauh, idiom, dan slang campuran kode.
Banyak kesalahan terjemahan adalah kegagalan konteks. Kata ganti, elipsis, dan tautan wacana memerlukan kesadaran di luar kalimat. Model tingkat dokumen mengkondisikan pada kalimat sekitarnya; terjemahan yang ditingkatkan dengan pengambilan mengambil segmen relevan dari sebelumnya dalam dokumen, panduan gaya, atau riwayat tiket dan memperhatikannya selama dekoding. Dalam obrolan dukungan, dekoding bertahap menghormati giliran pembicara dan mempertahankan register yang konsisten per peserta. Dalam salinan pemasaran, pilihan kecil—gelar, formalitas, ritme—dapat lebih penting daripada kesetiaan literal, dan ini sering diatur oleh lembar gaya dan aturan spesifik lokal yang disuntikkan ke dalam prompt atau batasan dekoding.
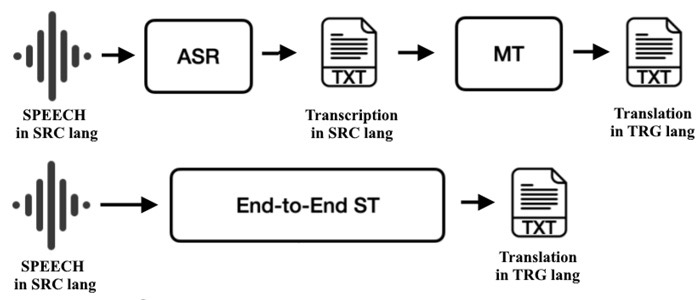
Ucapan, latensi, dan penggunaan langsung
Terjemahan ucapan memperkenalkan waktu dan prosodi. Sistem berurutan melakukan ASR → teks MT → TTS; setiap tahap dapat disesuaikan secara terpisah, dan cap waktu memungkinkan penyelarasan subtitle. Terjemahan suara-ke-teks end-to-end memetakan audio langsung ke teks bahasa lain, mengurangi kesalahan yang terakumulasi dan kadang-kadang mempertahankan frasa dengan lebih baik. Skenario langsung menekankan latensi. Sistem membagi audio menjadi potongan kecil, memberikan hipotesis parsial dengan cepat, dan merevisinya saat kepercayaan meningkat. Penanganan tanda baca dan ketidakjelasan yang hati-hati meningkatkan keterbacaan dalam keterangan dan mencegah ambiguitas dalam instruksi di mana koma yang hilang dapat mengubah makna.
Privasi, keamanan, dan auditabilitas
Terjemahan sering kali menyentuh konten sensitif: pesan pengguna, dokumen internal, catatan kesehatan, kontrak. Penerapan merespons dengan kontrol teknis dan prosedural. Input dan output dienkripsi dalam perjalanan dan saat istirahat; jendela retensi diminimalkan; informasi yang dapat diidentifikasi secara pribadi disembunyikan sebelum pemrosesan dan disisipkan kembali setelahnya. Kontrol akses membatasi siapa yang dapat melihat konten mentah dan output model. Untuk industri yang diatur, log audit mencatat versi model, prompt, parameter dekoding, tindakan editor, dan langkah persetujuan untuk merekonstruksi bagaimana sebuah kalimat mencapai publikasi. Filter konten mendeteksi kategori berisiko seperti kebencian atau diri sendiri; bagian yang ditandai mungkin memerlukan peninjau manusia tambahan bahkan jika bahasanya sendiri terlihat lancar.
Terminologi sering kali adalah tempat di mana kebenaran bertemu identitas. Tim produk mungkin bersikeras pada “Masuk” daripada “Log in,” atau pada frasa tertentu untuk klausul garansi. Sistem menegakkan pilihan ini melalui batasan keras, bias lunak, dan pemeriksaan validasi yang dijalankan setelah generasi. Memori terjemahan menyediakan kecocokan tepat dan kabur sehingga konten yang diulang tetap konsisten dan editor menghindari mengulang pekerjaan. Detail lokal yang tampak sepele—urutan alamat, pemisah desimal, format tanggal, kapitalisasi judul—menambah kredibilitas. Nama menyajikan kasus khusus: kebijakan transliterasi berbeda menurut pasar, dan beberapa merek selalu disimpan dalam skrip Latin sementara yang lain dilokalisasi.
Mode kegagalan umum—dan bagaimana tim menguranginya
-
Angka dan kode yang menyimpang selama generasi. Mekanisme salin dan validator pasca memastikan kode produk, harga, dan konversi unit tetap utuh. - String pendek yang ambigu. Tambahkan metadata (nama layar, audiens) untuk membedakan atau mengarahkan ke manusia; simpan mini-glossari untuk komponen UI.
- Parafrase berlebihan dari LLM umum. Gunakan dekoding yang dibatasi, penegakan istilah, dan NMT yang disesuaikan dengan domain sebelum penyempurnaan gaya.
- Data pelatihan yang bising atau tidak selaras. Kurasi korpus, selaraskan dengan hati-hati, dan karantina sumber yang memperkenalkan kesalahan sistematis.
- Mengabaikan preferensi lokal. Pertahankan panduan gaya per-lokal; uji varian dengan peninjau asli; hindari pengaturan global yang diam-diam menimpa norma lokal.
Mengintegrasikan terjemahan AI ke dalam produk
Pilihan rekayasa membentuk hasil sebanyak pilihan model. API cloud menawarkan cakupan bahasa yang luas dan kapasitas elastis; model yang dihosting sendiri memberikan kontrol dan tata kelola data yang lebih ketat; hibrida mengarahkan konten sensitif atau berisiko tinggi secara internal dan mengirimkan materi berisiko rendah ke luar. Pemrosesan batch meningkatkan throughput untuk pengiriman besar; API streaming mengurangi latensi yang dirasakan dalam obrolan dan pengaturan langsung. Kunci idempotensi dan pengulangan melindungi dari penerbitan duplikat. Observabilitas adalah hal yang tidak bisa dinegosiasikan: simpan pengidentifikasi yang di-hash untuk input dan output, anotasi kesalahan dengan kategori, dan permukaan dasbor yang menggabungkan metrik otomatis, skor manusia, dan KPI bisnis (waktu penyelesaian, biaya per kata, upaya pasca-editing).
Untuk ergonomi pengembang, buat terminologi dan memori terjemahan sebagai layanan kelas satu dengan API yang jelas daripada spreadsheet yang tersebar. Bangun saluran konten yang terlihat seperti sistem data modern mana pun: antrean, pekerja, toko fitur untuk glosari, dan pekerjaan evaluasi yang berjalan setiap malam pada suite pengujian statis. Buat gerbang untuk domain berisiko tinggi di mana publikasi otomatis dinonaktifkan oleh kebijakan. Dan saat menggunakan LLM, perlakukan prompt sebagai konfigurasi dengan versi, catatan perubahan, dan jalur rollback; sedikit perubahan pada prompt dapat mengubah nada dengan cara yang tidak terduga.
Teknologi bahasa belajar dari data yang mencerminkan pola dunia, termasuk biasnya. Kurasi, penghapusan duplikasi, dan audit mengurangi artefak yang berbahaya. Saat menerjemahkan konten yang dihasilkan pengguna, ungkapkan penggunaan terjemahan mesin di mana sesuai dan hormati persetujuan. Asal data penting: tim harus tahu dari mana korpus pelatihan dan penyesuaian berasal, lisensi apa yang berlaku, dan kewajiban apa yang mengikuti. Aksesibilitas adalah bagian dari tugas: varian bahasa yang sederhana mungkin diperlukan dalam beberapa konteks, dan sistem harus menghormati persyaratan tersebut sama ketatnya dengan mereka menghormati nada merek.
Terjemahan AI, maka, bukanlah panggilan model tunggal tetapi sistem yang terkoordinasi. Model belajar struktur lintas bahasa; aset data dan batasan mengarahkan mereka; estimasi kualitas dan editor manusia memberikan rem dan kemudi; lapisan privasi dan audit membuat proses dapat dipercaya; instrumentasi menunjukkan di mana harus meningkatkan selanjutnya. Ketika bagian-bagian tersebut dirancang untuk bekerja sama, organisasi tidak hanya memindahkan kata-kata antar bahasa—mereka mempertahankan niat, kejelasan, dan identitas di seluruh produk, pasar, dan media pada skala yang diminta oleh komunikasi modern.
Sistem terjemahan AI bergantung pada arsitektur pembelajaran mendalam—terutama Transformer—untuk memodelkan seluruh kalimat sebagai representasi kontekstual. Alih-alih bergantung pada probabilitas tingkat kata atau aturan tata bahasa yang didefinisikan secara manual, mereka belajar struktur linguistik implisit dari korpus paralel yang besar. Ini memungkinkan mereka untuk menggeneralisasi di berbagai domain dan menangani input kolokial atau tidak gramatikal dengan lebih efektif daripada sistem berbasis aturan atau statistik sebelumnya.
Data pelatihan adalah fondasi dari kemampuan penerjemah AI. Korpus dwibahasa yang bersih, spesifik domain, dan selaras dengan baik secara langsung mempengaruhi akurasi dan nada. Kebisingan, ketidakselarasan, atau ketidakcocokan domain dapat menyebarkan kesalahan sistematis ke dalam output. Untuk aplikasi berisiko tinggi seperti terjemahan hukum atau medis, dataset yang dikurasi dan glosari yang divalidasi oleh manusia sering kali diintegrasikan ke dalam tahap penyesuaian untuk mempertahankan presisi dan kontrol terminologi.
Saluran terjemahan perusahaan biasanya menggunakan injeksi istilah dan memori terjemahan untuk menjamin frasa yang konsisten. Selama dekoding, sistem dapat menegakkan istilah yang diperlukan secara dinamis melalui dekoding yang dibatasi. Batasan ini didukung oleh basis data linguistik dan sistem manajemen terminologi yang mendefinisikan kosakata yang disetujui berdasarkan merek, lokal, dan konteks regulasi. Alat evaluasi berkelanjutan mengukur seberapa konsisten mesin menghormati istilah tersebut di seluruh pembaruan.
Latensi diminimalkan melalui dekoding bertahap, pemrosesan audio yang terchunk, dan optimasi inferensi di perangkat. Alih-alih menunggu input lengkap, model streaming menghasilkan hipotesis parsial yang disempurnakan saat konteks baru tiba. Dalam terjemahan ucapan langsung, sistem mengorbankan sedikit margin akurasi untuk responsivitas, memprioritaskan waktu alami dan penyelarasan segmen. Kuantisasi model dan percepatan perangkat keras lebih lanjut mengurangi penundaan pemrosesan.
Tantangan utama termasuk propagasi bias, privasi data, dan keterlacakan. Korpus pelatihan sering kali mencerminkan bias sosial atau budaya yang dapat muncul kembali dalam output terjemahan. Penerapan yang bertanggung jawab menyamarkan data sensitif, menerapkan jejak audit untuk keputusan terjemahan, dan memungkinkan tinjauan manusia terhadap konten berdampak tinggi. Transparansi dalam asal data dan pengujian bias yang berkelanjutan menjadi persyaratan standar untuk saluran terjemahan AI yang patuh.