AI अनुवाद क्या है?
AI अनुवाद क्या है?
सामग्री की तालिका
-
नियमों से सीखे गए प्रतिनिधित्व तक - डेटा, संकेत, और अनुकूलन
- उत्पादन प्रणाली वास्तव में कैसे काम करती हैं
- भ्रम के बिना गुणवत्ता मापना
- संदर्भ राजा है
- भाषण, विलंब, और लाइव उपयोग
- गोपनीयता, सुरक्षा, और ऑडिट करने की क्षमता
- शब्दावली और स्थानीय बारीकियाँ
- सामान्य विफलता मोड—और टीमें उन्हें कैसे कम करती हैं
- उत्पादों में AI अनुवाद का एकीकरण
- नैतिकता और उत्पत्ति
- अक्सर पूछे जाने वाले प्रश्न
AI अनुवाद एक भाषा से दूसरी भाषा में अर्थ का स्वचालित रूपांतरण है, जो डेटा से सीखने के द्वारा किया जाता है न कि कठिन-कोडित व्याकरण नियमों से। यह अनुवाद को एक भविष्यवाणी समस्या के रूप में मानता है: एक भाषा में टोकनों के अनुक्रम को देखते हुए, दूसरे में एक अनुक्रम उत्पन्न करें जो अर्थ, स्वर, रजिस्टर, और प्रारूप को बनाए रखता है। इसकी विशिष्ट विशेषता केवल उन शब्दों को उत्पन्न करने वाली न्यूरल गणित नहीं है; यह मॉडल के चारों ओर का पारिस्थितिकी तंत्र है—डेटा पाइपलाइन्स, शब्दावली नियंत्रण, गुणवत्ता अनुमान, गोपनीयता सुरक्षा, संपादक कार्यप्रवाह, और उपकरण—जो कच्चे आउटपुट को विश्वसनीय बहुभाषी संचार में बदलता है।
नियमों से सीखे गए प्रतिनिधित्व तक
मशीन अनुवाद दृष्टिकोणों का विकास—नियम-आधारित प्रणालियों से न्यूरल प्रतिनिधित्व तक।
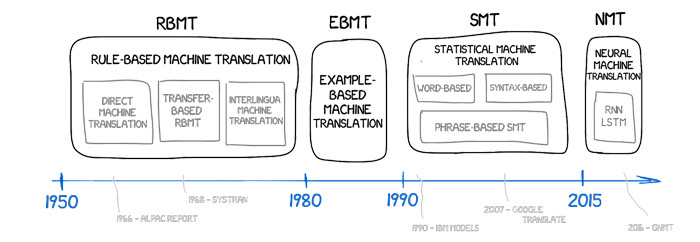
प्रारंभिक प्रणालियों ने हाथ से व्याकरण को कोडित करने का प्रयास किया, भाषण के भागों और वाक्य संरचनाओं को जटिल नियम सेट के साथ मैप किया। सांख्यिकीय मशीन अनुवाद ने नियमों को शब्दों और वाक्यांशों पर संभावनाओं से बदल दिया जो संरेखित कॉर्पस से निकाले गए थे। वर्तमान मानक न्यूरल मशीन अनुवाद (NMT) है, जहां एकल नेटवर्क स्रोत वाक्य का घनत्व वेक्टर के रूप में प्रतिनिधित्व करना और लक्ष्य वाक्य को टोकन द्वारा टोकन डिकोड करना सीखता है। आधुनिक NMT आमतौर पर ट्रांसफार्मर आर्किटेक्चर पर आधारित होता है। इसका ध्यान तंत्र मॉडल को पूरे अनुक्रम में संबंधों को तौलने की अनुमति देता है, लंबी दूरी की निर्भरताओं और लचीले शब्द क्रम को पकड़ता है। शब्दावली को प्रबंधनीय रखने के लिए जबकि व्याकरण और दुर्लभ नामों को कवर किया जा सके, टोकनाइजेशन उपशब्द इकाइयों जैसे बाइट-पेयर एन्कोडिंग या सेंटेंसपीस पर निर्भर करता है।
बड़े भाषा मॉडल (LLMs) इस दृष्टिकोण को बढ़ाते हैं। विशाल बहुभाषी कॉर्पस पर प्रशिक्षित और सामान्य तर्क के लिए निर्देशित, वे कई क्षमताओं में से एक के रूप में अनुवाद कर सकते हैं, जैसे कि आंशिक वाक्य, मिश्रित मार्कअप, या चैट सपोर्ट लॉग जैसी गंदे इनपुट को संभालना। उनकी बहुपरकारीता सहायक है, लेकिन खुली पीढ़ी चुनौतियाँ लाती है: जहां सटीकता की आवश्यकता होती है, वहां पैराफ्रेज़ करें, या विवरणों के आत्मविश्वास से भरे दावे जो स्रोत में कभी मौजूद नहीं थे। उत्पादन प्रणालियाँ अक्सर एक मजबूत NMT इंजन को एक LLM चरण के साथ जोड़ती हैं जो टोन को समायोजित करता है जबकि सीमित डिकोडिंग और शब्दावली इंजेक्शन महत्वपूर्ण शब्दों की रक्षा करते हैं।
उच्च गुणवत्ता वाले समानांतर कॉर्पस रीढ़ हैं। अदालतें, संसद, उपशीर्षक, डेवलपर पोर्टल, और द्विभाषी वेबसाइटें पर्यवेक्षित शिक्षण के लिए संरेखित वाक्य जोड़े प्रदान करती हैं। एकल-भाषी पाठ भी महत्वपूर्ण है। बैक-अनुवाद के साथ, लक्ष्य-भाषा वाक्य स्रोत में अनुवादित होते हैं ताकि अतिरिक्त जोड़े बनाए जा सकें, जो कम संसाधन दिशाओं में प्रवाह और कवरेज में सुधार करते हैं। आत्म-प्रशिक्षण विविधताएँ और शोर-चैनल उद्देश्य मॉडल को प्राकृतिक लक्ष्य आउटपुट की ओर और अधिक पूर्वाग्रहित करते हैं।
डोमेन अनुकूलन वह जगह है जहां सामान्य क्षमता व्यावसायिक मूल्य बन जाती है। एक सामान्य मॉडल जो समाचार और वेब पृष्ठों पर अच्छा प्रदर्शन करता है, कानूनी बायलॉज़, नैदानिक पत्तियों, या पेटेंट सारांशों पर असफल हो सकता है। यहां तक कि डोमेन सामग्री की मामूली मात्रा पर ठीक-ठाक करना—शब्दावली सूचियों और अनुवाद स्मृतियों द्वारा बढ़ाया गया—शैली और शब्दावली को नाटकीय रूप से बदल सकता है। पैरामीटर-कुशल तकनीकें (एडाप्टर, LoRA) टीमों को पूरे मॉडल को फिर से प्रशिक्षित किए बिना कई डोमेन व्यक्तित्व बनाए रखने की अनुमति देती हैं। समय के साथ, पोस्ट-संपादक सुधार और रेटिंग प्रशिक्षण संकेत बन जाते हैं: फीडबैक लूप जो प्रणाली को एक संगठन की पसंदीदा आवाज की ओर ले जाते हैं।
उत्पादन प्रणाली वास्तव में कैसे काम करती हैं
वास्तविक तैनाती किसी भी टोकन के उत्पन्न होने से पहले शुरू होती है। सामग्री को सामान्यीकृत, खंडित, और भाषा-निर्धारित किया जाता है; प्लेसहोल्डर और मार्कअप की पहचान की जाती है ताकि उन्हें संरक्षित किया जा सके। अत्यधिक दोहराए जाने वाले स्ट्रिंग—UI लेबल, उत्पाद कोड, ईमेल टेम्पलेट—जल्दी पहचाने जाते हैं और अक्सर अनुवाद को बायपास करते हैं या सटीक रूपांतरों तक सीमित होते हैं। इंजन स्रोत को कोडित करता है, लक्ष्य को बीम खोज या सीमित नमूनाकरण के साथ डिकोड करता है, और केसिंग और स्पेसिंग को बहाल करने के लिए डिकोड करता है। पोस्ट-प्रोसेसिंग टैग, नंबर, और नामित संस्थाओं को फिर से डालती है। एक गुणवत्ता अनुमान मॉडल आत्मविश्वास की भविष्यवाणी करता है, निम्न-आत्मविश्वास खंडों को मानव संपादकों की ओर मार्गदर्शन करता है जबकि उच्च-आत्मविश्वास वाले खंडों को तब प्रकाशित करने की अनुमति देता है जब विलंबता महत्वपूर्ण होती है।
कुछ लीवर अनुवाद की विशेषताओं को परिभाषित करते हैं:
- सीमित डिकोडिंग: आवश्यक शर्तें प्रकट होनी चाहिए, भाषाई रूप से समृद्ध भाषाओं के लिए रूपांतरणीय लचीलापन के साथ।
- शब्दावली इंजेक्शन और स्मृतियाँ: पसंदीदा रूपांतरण और पहले से अनुमोदित वाक्य आउटपुट को स्थिरता की ओर ले जाते हैं।
- जोखिम मार्गदर्शन: गुणवत्ता अनुमान स्वचालित प्रकाशन बनाम पोस्ट-संपादन के लिए थ्रेशोल्ड सेट करता है, लागत, गति, और सटीकता का संतुलन बनाता है।
कंप्यूटर-सहायता प्राप्त अनुवाद उपकरण संपादकों के लिए कॉकपिट प्रदान करते हैं। सुझाव उनके टाइप करते समय अपडेट होते हैं; डिफ्स पोस्ट-संपादन प्रयास को मापते हैं; कीस्ट्रोक और समय मेट्रिक्स दिखाते हैं कि मॉडल कहाँ संघर्ष करते हैं। ये ट्रेस प्रशिक्षण डेटा चयन और मॉडल अपडेट को सूचित करते हैं। उपकरण आवश्यक हैं: विलंबता, थ्रूपुट, त्रुटि प्रकार, और संपादक प्रयास को स्थानीय और डोमेन द्वारा ट्रैक किया जाता है। टीमें एक डैशबोर्ड मेट्रिक से उस सटीक वाक्य तक जा सकती हैं जिसने एक रिग्रेशन का कारण बना।
स्वचालित मेट्रिक्स तेज़ फीडबैक प्रदान करते हैं। BLEU और chrF n-ग्राम ओवरलैप या वर्ण-स्तरीय समानता को मापते हैं; COMET जैसे सीखे गए मेट्रिक्स मानव निर्णयों के साथ बेहतर सहसंबंध रखते हैं, आउटपुट और संदर्भों की तुलना करके न्यूरल एन्कोडर्स के माध्यम से। संदर्भ-मुक्त गुणवत्ता अनुमान केवल स्रोत और परिकल्पना का उपयोग करके एक स्कोर और यहां तक कि त्रुटि स्पैन की भविष्यवाणी करता है, वास्तविक समय में मार्गदर्शन सक्षम करता है। फिर भी इनमें से कोई भी मानव समीक्षा का स्थान नहीं लेता। भाषाविज्ञानी पर्याप्तता (अर्थ संरक्षित) और प्रवाह (प्राकृतिकता) की जांच करते हैं, और वे डोमेन-विशिष्ट चेकलिस्ट लागू करते हैं: क्या आउटपुट ब्रांड की आवाज, कानूनी वाक्यांश, contraindication शब्दावली, और नामों, पते, और दशमलव के लिए स्थानीय परंपराओं का सम्मान करता है? अच्छे कार्यक्रम स्वचालित डैशबोर्ड को समय-समय पर अंधे मानव मूल्यांकन के साथ मिलाते हैं, जिसमें कठिन घटनाओं जैसे लंबी दूरी के समझौते, मुहावरे, और कोड-मिश्रित स्लैंग शामिल होते हैं।
कई अनुवाद त्रुटियाँ संदर्भ की विफलताएँ हैं। सर्वनाम, उपसर्ग, और संवाद लिंक वाक्य से परे जागरूकता की आवश्यकता होती है। दस्तावेज़-स्तरीय मॉडल आस-पास के वाक्यों पर शर्त रखते हैं; पुनर्प्राप्ति-संवर्धित अनुवाद दस्तावेज़ के पहले से प्रासंगिक खंडों को लाता है, शैली गाइड, या टिकट इतिहास और डिकोडिंग के दौरान उन पर ध्यान केंद्रित करता है। समर्थन चैट में, क्रमिक डिकोडिंग वक्ता के मोड़ का सम्मान करता है और प्रत्येक प्रतिभागी के लिए लगातार रजिस्टर बनाए रखता है। मार्केटिंग कॉपी में, छोटे विकल्प—सम्मान, औपचारिकता, लय—शाब्दिक निष्ठा से अधिक महत्वपूर्ण हो सकते हैं, और ये अक्सर शैली पत्रिकाओं और स्थानीय-विशिष्ट नियमों द्वारा नियंत्रित होते हैं जो संकेतों या डिकोडिंग प्रतिबंधों में इंजेक्ट किए जाते हैं।
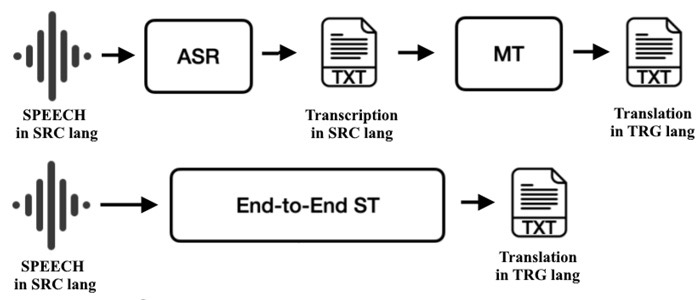
भाषण अनुवाद समय और प्रोसोड़ी को पेश करता है। कैस्केडेड सिस्टम ASR → टेक्स्ट MT → TTS करते हैं; प्रत्येक चरण को अलग से ट्यून किया जा सकता है, और टाइमस्टैम्प उपशीर्षक संरेखण की अनुमति देते हैं। एंड-टू-एंड स्पीच-टू-टेक्स्ट अनुवाद ऑडियो को सीधे दूसरी भाषा के टेक्स्ट में मैप करता है, संचित त्रुटियों को कम करता है और कभी-कभी वाक्यांश को बेहतर बनाए रखता है। लाइव परिदृश्यों में विलंबता पर जोर दिया जाता है। सिस्टम ऑडियो को छोटे टुकड़ों में विभाजित करते हैं, आंशिक परिकल्पनाएँ जल्दी प्रदान करते हैं, और जैसे-जैसे आत्मविश्वास बढ़ता है, उन्हें संशोधित करते हैं। सावधानीपूर्वक विराम चिह्न और असंगति प्रबंधन कैप्शन में पठनीयता में सुधार करता है और निर्देशों में अस्पष्टता को रोकता है जहां एक गायब अल्पविराम अर्थ बदल सकता है।
गोपनीयता, सुरक्षा, और ऑडिट करने की क्षमता
अनुवाद अक्सर संवेदनशील सामग्री को छूता है: उपयोगकर्ता संदेश, आंतरिक दस्तावेज़, स्वास्थ्य रिकॉर्ड, अनुबंध। तैनाती तकनीकी और प्रक्रियात्मक नियंत्रणों के साथ प्रतिक्रिया करती है। इनपुट और आउटपुट को ट्रांजिट और रेस्ट में एन्क्रिप्ट किया जाता है; रिटेंशन विंडो को न्यूनतम किया जाता है; व्यक्तिगत पहचान योग्य जानकारी को प्रसंस्करण से पहले मास्क किया जाता है और बाद में फिर से डाला जाता है। एक्सेस नियंत्रण यह सीमित करते हैं कि कौन कच्ची सामग्री और मॉडल आउटपुट देख सकता है। विनियमित उद्योगों के लिए, ऑडिट लॉग मॉडल संस्करणों, संकेतों, डिकोडिंग पैरामीटर, संपादक क्रियाएँ, और अनुमोदन चरणों को रिकॉर्ड करते हैं ताकि यह पुनर्निर्माण किया जा सके कि एक वाक्य प्रकाशन तक कैसे पहुंचा। सामग्री फ़िल्टर जोखिम भरे श्रेणियों जैसे नफरत या आत्म-हानि का पता लगाते हैं; ध्वजांकित अंशों को एक अतिरिक्त मानव समीक्षक की आवश्यकता हो सकती है, भले ही भाषा स्वयं प्रवाह में दिखती हो।
शब्दावली अक्सर वह जगह होती है जहां सही होना पहचान से मिलता है। एक उत्पाद टीम "साइन इन" पर जोर दे सकती है बजाय "लॉग इन" के, या वारंटी खंड के लिए एक विशिष्ट वाक्यांश पर। प्रणाली इन विकल्पों को कठिन प्रतिबंधों, नरम पूर्वाग्रहों, और जनरेशन के बाद चलने वाले सत्यापन जांचों के माध्यम से लागू करती है। अनुवाद स्मृतियाँ सटीक और धुंधले मिलान प्रदान करती हैं ताकि दोहराए जाने वाले सामग्री स्थिर रहें और संपादक काम को फिर से करने से बचें। स्थानीय विवरण जो मामूली लगते हैं—पता क्रम, दशमलव विभाजक, दिनांक प्रारूप, शीर्षक पूंजीकरण—विश्वसनीयता में जोड़ते हैं। नाम विशेष मामलों को प्रस्तुत करते हैं: ट्रांसलिटरेशन नीतियाँ बाजार के अनुसार भिन्न होती हैं, और कुछ ब्रांड हमेशा लैटिन लिपि में रखे जाते हैं जबकि अन्य को स्थानीयकृत किया जाता है।
सामान्य विफलता मोड—और टीमें उन्हें कैसे कम करती हैं
-
उत्पादन के दौरान संख्याएँ और कोड भटकना। कॉपी तंत्र और पोस्ट-वैधता सुनिश्चित करते हैं कि उत्पाद कोड, मूल्य, और इकाई रूपांतरण बरकरार रहें। - अस्पष्ट छोटे स्ट्रिंग। अस्पष्टता को दूर करने या मानवों को मार्गदर्शन करने के लिए मेटाडेटा (स्क्रीन नाम, दर्शक) जोड़ें; UI घटकों के लिए लघु-ग्लोसरी बनाए रखें।
- सामान्य LLMs से अधिक-पैराफ्रेज़। शैलीगत परिष्करण से पहले सीमित डिकोडिंग, शब्दावली प्रवर्तन, और एक डोमेन-ट्यून NMT पास का उपयोग करें।
- शोर या असंगत प्रशिक्षण डेटा। कॉर्पस को क्यूरेट करें, सावधानी से संरेखित करें, और उन स्रोतों को क्वारंटाइन करें जो प्रणालीगत त्रुटियाँ पेश करते हैं।
- स्थानीय प्राथमिकताओं की अनदेखी। प्रति-स्थानीय शैली गाइड बनाए रखें; मूल समीक्षकों के साथ रूपांतरों का परीक्षण करें; वैश्विक सेटिंग्स से बचें जो चुपचाप स्थानीय मानदंडों को ओवरराइड करती हैं।
उत्पादों में AI अनुवाद का एकीकरण
इंजीनियरिंग विकल्प परिणामों को मॉडल विकल्प के रूप में आकार देते हैं। क्लाउड APIs व्यापक भाषा कवरेज और लचीली क्षमता प्रदान करते हैं; स्वयं-होस्टेड मॉडल नियंत्रण और डेटा शासन प्रदान करते हैं; हाइब्रिड संवेदनशील या उच्च-जोखिम सामग्री को आंतरिक रूप से मार्गदर्शन करते हैं और कम-जोखिम सामग्री को बाहर भेजते हैं। बैच प्रसंस्करण बड़े ड्रॉप के लिए थ्रूपुट में सुधार करता है; स्ट्रीमिंग APIs चैट और लाइव सेटिंग्स में अनुभव की गई विलंबता को कम करते हैं। आइडेम्पोटेंसी कुंजी और पुनः प्रयास डुप्लिकेट प्रकाशन के खिलाफ सुरक्षा करते हैं। अवलोकन अनिवार्य है: इनपुट और आउटपुट के लिए हैश किए गए पहचानकर्ताओं को स्टोर करें, श्रेणियों के साथ त्रुटियों को एनोटेट करें, और स्वचालित मेट्रिक्स, मानव स्कोर, और व्यावसायिक KPI (टर्नअराउंड समय, प्रति शब्द लागत, पोस्ट-संपादन प्रयास) को संयोजित करने वाले डैशबोर्ड को सतह करें।
डेवलपर एर्गोनॉमिक्स के लिए, शब्दावली और अनुवाद स्मृति को स्पष्ट APIs के साथ प्रथम श्रेणी की सेवाएँ बनाएं न कि बिखरे हुए स्प्रेडशीट। एक सामग्री पाइपलाइन बनाएं जो किसी भी आधुनिक डेटा प्रणाली की तरह दिखती है: कतारें, श्रमिक, शब्दावली के लिए विशेषताएँ, और स्थिर परीक्षण सूट पर रात भर चलने वाली मूल्यांकन नौकरियाँ। उच्च-जोखिम डोमेन के लिए गेट बनाएँ जहाँ स्वचालित प्रकाशन नीति द्वारा अक्षम है। और जब LLMs का उपयोग करते हैं, तो संकेतों को कॉन्फ़िगरेशन के रूप में मानें जिसमें संस्करण, परिवर्तन लॉग, और रोलबैक पथ होते हैं; एक छोटा संकेत संशोधन अप्रत्याशित तरीकों से स्वर को बदल सकता है।
भाषा प्रौद्योगिकियाँ डेटा से सीखती हैं जो दुनिया के पैटर्न को दर्शाती हैं, जिसमें इसके पूर्वाग्रह भी शामिल हैं। क्यूरेशन, डुप्लिकेशन, और ऑडिटिंग हानिकारक कलाकृतियों को कम करते हैं। जब उपयोगकर्ता-जनित सामग्री का अनुवाद करते हैं, तो मशीन अनुवाद के उपयोग का खुलासा करें जहाँ उपयुक्त हो और सहमति का सम्मान करें। डेटा उत्पत्ति महत्वपूर्ण है: टीमों को यह जानना चाहिए कि प्रशिक्षण और फाइन-ट्यूनिंग कॉर्पस कहाँ से आया, कौन से लाइसेंस लागू होते हैं, और कौन सी बाधाएँ आती हैं। पहुंचनीयता इस कार्य का एक हिस्सा है: कुछ संदर्भों में सरल भाषा के रूपांतर आवश्यक हो सकते हैं, और प्रणालियों को उन आवश्यकताओं का सम्मान करना चाहिए जैसे वे ब्रांड के स्वर का सम्मान करती हैं।
AI अनुवाद, फिर, एक एकल मॉडल कॉल नहीं है बल्कि एक समन्वित प्रणाली है। मॉडल क्रॉस-लिंगुअल संरचना सीखते हैं; डेटा संपत्तियाँ और प्रतिबंध उन्हें मार्गदर्शन करते हैं; गुणवत्ता अनुमान और मानव संपादक ब्रेक और स्टीयरिंग प्रदान करते हैं; गोपनीयता और ऑडिट परतें प्रक्रिया को विश्वसनीय बनाती हैं; उपकरण दिखाते हैं कि अगली बार कहाँ सुधार करना है। जब ये टुकड़े एक साथ काम करने के लिए डिज़ाइन किए जाते हैं, तो संगठन केवल भाषाओं के बीच शब्दों को नहीं ले जाते—वे उत्पादों, बाजारों, और माध्यमों के बीच इरादे, स्पष्टता, और पहचान को बनाए रखते हैं, जिस पैमाने की आधुनिक संचार की मांग होती है।
AI अनुवाद प्रणाली गहरे शिक्षण आर्किटेक्चर—विशेष रूप से ट्रांसफार्मर—का उपयोग करती हैं ताकि पूरे वाक्यों को संदर्भात्मक प्रतिनिधित्व के रूप में मॉडल किया जा सके। शब्द-स्तरीय संभावनाओं या मैन्युअल रूप से परिभाषित व्याकरण नियमों पर निर्भर रहने के बजाय, वे बड़े समानांतर कॉर्पस से निहित भाषाई संरचनाओं को सीखती हैं। यह उन्हें डोमेन के पार सामान्यीकृत करने और बोलचाल या व्याकरणिक रूप से गलत इनपुट को पहले के नियम-आधारित या सांख्यिकीय प्रणालियों की तुलना में अधिक प्रभावी ढंग से संभालने की अनुमति देता है।
प्रशिक्षण डेटा AI अनुवादक की क्षमता की नींव है। साफ, डोमेन-विशिष्ट, और अच्छी तरह से संरेखित द्विभाषी कॉर्पस सीधे सटीकता और स्वर को प्रभावित करते हैं। शोर, असंगतता, या डोमेन असंगति प्रणालीगत त्रुटियों को आउटपुट में प्रवाहित कर सकती है। कानूनी या चिकित्सा अनुवाद जैसे उच्च-जोखिम अनुप्रयोगों के लिए, क्यूरेटेड डेटासेट और मानव-मान्यताप्राप्त शब्दावली अक्सर फाइन-ट्यूनिंग चरणों में एकीकृत की जाती हैं ताकि सटीकता और शब्दावली नियंत्रण बनाए रखा जा सके।
उद्यम अनुवाद पाइपलाइनों में आमतौर पर शब्दावली इंजेक्शन और अनुवाद स्मृतियों का उपयोग किया जाता है ताकि स्थिर वाक्यांशों की गारंटी दी जा सके। डिकोडिंग के दौरान, प्रणाली आवश्यक शर्तों को गतिशील रूप से सीमित डिकोडिंग के माध्यम से लागू कर सकती है। ये प्रतिबंध भाषाई डेटाबेस और शब्दावली प्रबंधन प्रणालियों द्वारा समर्थित होते हैं जो ब्रांड, स्थानीय, और नियामक संदर्भ के अनुसार अनुमोदित शब्दावली को परिभाषित करते हैं। निरंतर मूल्यांकन उपकरण मापते हैं कि इंजन उन शर्तों का सम्मान कितनी स्थिरता से करता है।
विलंबता को क्रमिक डिकोडिंग, खंडित ऑडियो प्रसंस्करण, और डिवाइस पर अनुमान अनुकूलन के माध्यम से न्यूनतम किया जाता है। पूर्ण इनपुट की प्रतीक्षा करने के बजाय, स्ट्रीमिंग मॉडल आंशिक परिकल्पनाएँ उत्पन्न करते हैं जो नए संदर्भ के आने पर परिष्कृत होती हैं। लाइव भाषण अनुवाद में, सिस्टम प्रतिक्रियाशीलता के लिए एक छोटी सटीकता सीमा का व्यापार करते हैं, प्राकृतिक समय और खंड संरेखण को प्राथमिकता देते हैं। मॉडल क्वांटाइजेशन और हार्डवेयर त्वरक प्रसंस्करण में देरी को और कम करते हैं।
मुख्य चुनौतियों में पूर्वाग्रह प्रसार, डेटा गोपनीयता, और ट्रेसबिलिटी शामिल हैं। प्रशिक्षण कॉर्पस अक्सर सामाजिक या सांस्कृतिक पूर्वाग्रहों को दर्शाते हैं जो अनुवादित आउटपुट में फिर से प्रकट हो सकते हैं। जिम्मेदार तैनाती संवेदनशील डेटा को गुमनाम बनाती है, अनुवाद निर्णयों के लिए ऑडिट ट्रेल्स लागू करती है, और उच्च-प्रभाव सामग्री की मानव समीक्षा की अनुमति देती है। डेटा उत्पत्ति में पारदर्शिता और निरंतर पूर्वाग्रह परीक्षण अनुपालन AI अनुवाद पाइपलाइनों के लिए मानक आवश्यकताएँ बनती जा रही हैं।