Qu'est-ce que la traduction par IA ?
Qu'est-ce que la traduction par IA ?
Table des matières
-
Des règles aux représentations apprises - Données, signaux et adaptation
- Comment fonctionnent réellement les systèmes de production
- Mesurer la qualité sans illusions
- Le contexte est roi
- Parole, latence et utilisation en direct
- Confidentialité, sécurité et auditabilité
- Terminologie et nuances locales
- Modes d'échec communs—et comment les équipes les atténuent
- Intégrer la traduction par IA dans les produits
- Éthique et provenance
- FAQs
La traduction par IA est le rendu automatisé de la signification d'une langue à une autre en apprenant à partir de données plutôt qu'en codant des règles grammaticales. Elle traite la traduction comme un problème de prédiction : étant donné une séquence de tokens dans une langue, produire une séquence dans l'autre qui préserve le sens, le ton, le registre et le formatage. La caractéristique distinctive n'est pas seulement le calcul neuronal qui génère des mots ; c'est l'écosystème autour des modèles—les pipelines de données, le contrôle de la terminologie, l'estimation de la qualité, les protections de la vie privée, les flux de travail des éditeurs et l'instrumentation—qui transforme les sorties brutes en communication multilingue fiable.
Des règles aux représentations apprises
Évolution des approches de traduction automatique—des systèmes basés sur des règles aux représentations neuronales.
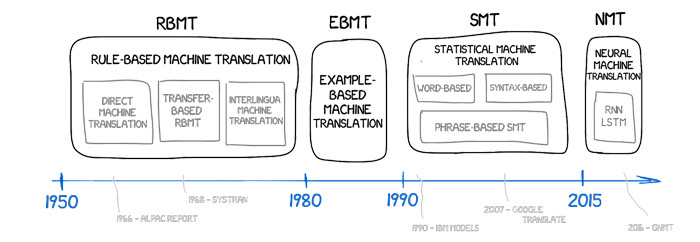
Les premiers systèmes ont tenté d'encoder les grammaires à la main, en cartographiant les parties du discours et les structures de phrases avec des ensembles de règles élaborés. La traduction automatique statistique a remplacé les règles par des probabilités sur des mots et des phrases extraites de corpus alignés. La norme actuelle est la traduction automatique neuronale (NMT), où un seul réseau apprend à représenter la phrase source sous forme de vecteurs denses et à décoder une phrase cible token par token. La NMT moderne est généralement construite sur l'architecture Transformer. Son mécanisme d'attention permet au modèle de peser les relations à travers l'ensemble de la séquence, capturant les dépendances à long terme et un ordre de mots flexible. Pour garder les vocabulaires gérables tout en couvrant les inflexions et les noms rares, la tokenisation repose sur des unités de sous-mots telles que l'encodage par paires de bytes ou SentencePiece.
Les grands modèles de langage (LLMs) étendent cette approche. Entraînés sur d'énormes corpus multilingues et ajustés pour le raisonnement général, ils peuvent traduire comme une capacité parmi d'autres, gérant des entrées désordonnées comme des phrases partielles, des balisages mélangés ou des journaux de support bavards. Leur polyvalence est utile, mais la génération ouverte pose des défis : paraphraser là où la précision est requise, ou faire des affirmations confiantes sur des détails qui n'étaient jamais présents dans la source. Les systèmes de production associent souvent un moteur NMT puissant à une étape LLM qui ajuste le ton tout en garantissant que le décodage contraint et l'injection de termes protègent le wording critique.
Données, signaux et adaptation
Des corpus parallèles de haute qualité sont la colonne vertébrale. Les tribunaux, les parlements, les sous-titres, les portails pour développeurs et les sites Web bilingues fournissent des paires de phrases alignées pour l'apprentissage supervisé. Le texte monolingue est également important. Avec la rétro-traduction, les phrases en langue cible sont traduites dans la source pour synthétiser des paires supplémentaires, améliorant la fluidité et la couverture dans les directions à faibles ressources. Les variantes d'auto-formation et les objectifs de canal bruyant biaisent encore davantage les modèles vers une sortie cible naturelle.
L'adaptation au domaine est là où la compétence générique devient valeur commerciale. Un modèle général qui fonctionne bien sur des nouvelles et des pages Web peut faiblir sur des documents juridiques, des brochures cliniques ou des résumés de brevets. Un ajustement même sur des quantités modestes de matériel de domaine—augmenté par des listes de terminologie et des mémoires de traduction—peut changer le style et la terminologie de manière spectaculaire. Les techniques efficaces en paramètres (adaptateurs, LoRA) permettent aux équipes de maintenir plusieurs personnalités de domaine sans réentraîner l'ensemble du modèle. Au fil du temps, les corrections et les évaluations des post-éditeurs deviennent des signaux d'entraînement : des boucles de rétroaction qui déplacent le système vers la voix préférée d'une organisation.
Comment fonctionnent réellement les systèmes de production
Les déploiements réels commencent avant qu'un token ne soit généré. Le contenu est normalisé, segmenté et détecté par langue ; les espaces réservés et le balisage sont identifiés afin qu'ils puissent être préservés. Les chaînes hautement répétables—étiquettes d'interface utilisateur, codes produits, modèles d'e-mail—sont reconnues tôt et souvent contournent la traduction ou sont contraintes à des variantes exactes. Le moteur encode la source, décode la cible avec une recherche par faisceau ou un échantillonnage contraint, et détokenise pour restaurer la casse et l'espacement. Le post-traitement réinsère des balises, des nombres et des entités nommées. Un modèle d'estimation de la qualité prédit la confiance, dirigeant les segments à faible confiance vers des éditeurs humains tout en permettant à ceux à haute confiance de publier lorsque la latence est importante.
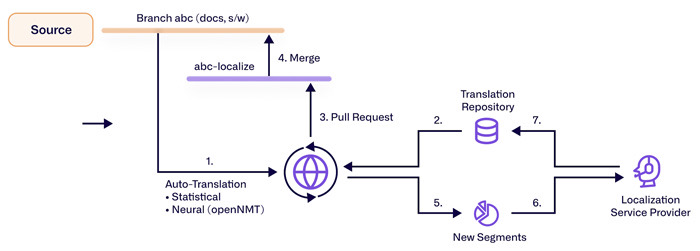
Quelques leviers définissent les caractéristiques de la traduction :
- Décodage contraint : les termes requis doivent apparaître, avec flexibilité d'inflexion pour les langues morphologiquement riches.
- Injection de termes et mémoires : les variantes préférées et les phrases précédemment approuvées orientent les sorties vers la cohérence.
- Routage des risques : l'estimation de la qualité fixe des seuils pour la publication automatique contre la post-édition, équilibrant coût, vitesse et précision.
Les outils de traduction assistée par ordinateur fournissent le cockpit pour les éditeurs. Les suggestions se mettent à jour au fur et à mesure qu'ils tapent ; les différences mesurent l'effort de post-édition ; les métriques de frappe et de temps montrent où les modèles rencontrent des difficultés. Ces traces informent la sélection des données d'entraînement et les mises à jour des modèles. L'instrumentation est essentielle : la latence, le débit, les types d'erreurs et l'effort des éditeurs sont suivis par région et domaine. Les équipes peuvent passer d'une métrique de tableau de bord à la phrase exacte qui a causé une régression.
Mesurer la qualité sans illusions
Les métriques automatiques fournissent un retour rapide. BLEU et chrF mesurent le chevauchement des n-grammes ou la similarité au niveau des caractères ; les métriques apprises comme COMET corrèlent mieux avec les jugements humains en comparant les sorties et les références à travers des encodeurs neuronaux. L'estimation de la qualité sans référence prédit un score et même des plages d'erreurs en utilisant uniquement la source et l'hypothèse, permettant un routage en temps réel. Pourtant, aucune de ces méthodes ne remplace l'examen humain. Les linguistes vérifient l'adéquation (sens préservé) et la fluidité (naturel), et ils appliquent des listes de contrôle spécifiques au domaine : la sortie respecte-t-elle la voix de la marque, la formulation légale, le wording des contre-indications et les conventions locales pour les noms, adresses et décimales ? De bons programmes mélangent des tableaux de bord automatisés avec des évaluations humaines périodiques, semées de phénomènes difficiles tels que l'accord à longue distance, les idiomes et l'argot mélangé.
De nombreuses erreurs de traduction sont des échecs de contexte. Les pronoms, l'ellipse et les liens discursifs nécessitent une conscience au-delà de la phrase. Les modèles au niveau du document conditionnent sur les phrases environnantes ; la traduction augmentée par récupération récupère des segments pertinents d'un document antérieur, de guides de style ou d'historiques de tickets et y prête attention lors du décodage. Dans le chat de support, le décodage incrémental respecte les tours de parole et maintient un registre cohérent par participant. Dans les textes marketing, de petits choix—titres honorifiques, formalité, rythme—peuvent avoir plus d'importance que la fidélité littérale, et ceux-ci sont souvent régis par des feuilles de style et des règles spécifiques à la locale injectées dans les invites ou les contraintes de décodage.
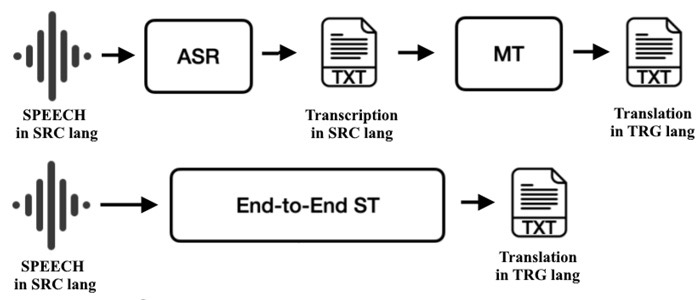
Parole, latence et utilisation en direct
La traduction de la parole introduit le timing et la prosodie. Les systèmes en cascade effectuent ASR → MT texte → TTS ; chaque étape peut être ajustée séparément, et les horodatages permettent l'alignement des sous-titres. La traduction de la parole à texte de bout en bout mappe l'audio directement dans le texte d'une autre langue, réduisant les erreurs cumulatives et préservant parfois mieux la formulation. Les scénarios en direct mettent l'accent sur la latence. Les systèmes segmentent l'audio en petits morceaux, livrent rapidement des hypothèses partielles et les révisent à mesure que la confiance augmente. Une ponctuation soignée et une gestion des disfluences améliorent la lisibilité des sous-titres et préviennent l'ambiguïté dans les instructions où une virgule manquante peut changer le sens.
Confidentialité, sécurité et auditabilité
La traduction touche souvent à des contenus sensibles : messages des utilisateurs, documents internes, dossiers de santé, contrats. Les déploiements répondent par des contrôles techniques et procéduraux. Les entrées et sorties sont cryptées en transit et au repos ; les fenêtres de conservation sont minimisées ; les informations personnellement identifiables sont masquées avant le traitement et réinsérées après. Les contrôles d'accès restreignent qui peut voir le contenu brut et les sorties du modèle. Pour les industries réglementées, les journaux d'audit enregistrent les versions des modèles, les invites, les paramètres de décodage, les actions des éditeurs et les étapes d'approbation pour reconstruire comment une phrase a atteint la publication. Des filtres de contenu détectent des catégories à risque telles que la haine ou l'automutilation ; les passages signalés peuvent nécessiter un examen humain supplémentaire même si la langue elle-même semble fluide.
Terminologie et nuances locales
La terminologie est souvent là où la justesse rencontre l'identité. Une équipe produit pourrait insister sur “Se connecter” plutôt que “S'identifier,” ou sur une formulation spécifique pour une clause de garantie. Le système impose ces choix par des contraintes strictes, des biais souples et des vérifications de validation qui s'exécutent après la génération. Les mémoires de traduction fournissent des correspondances exactes et floues afin que le contenu répété reste cohérent et que les éditeurs évitent de refaire le travail. Les détails locaux qui semblent mineurs—ordre des adresses, séparateurs décimaux, formats de date, capitalisation des titres—s'additionnent à la crédibilité. Les noms présentent des cas particuliers : les politiques de translittération diffèrent selon le marché, et certaines marques sont toujours conservées en script latin tandis que d'autres sont localisées.
Modes d'échec communs—et comment les équipes les atténuent
-
Chiffres et codes dérivant pendant la génération. Les mécanismes de copie et les post-validateurs garantissent que les codes produits, les prix et les conversions d'unités restent intacts. - Chaînes courtes ambiguës. Ajouter des métadonnées (nom d'écran, public) pour désambiguïser ou diriger vers des humains ; garder des mini-glossaires pour les composants de l'interface utilisateur.
- Trop de paraphrase des LLMs généraux. Utiliser le décodage contraint, l'application de termes et un passage NMT ajusté au domaine avant le raffinement stylistique.
- Données d'entraînement bruyantes ou mal alignées. Curatez les corpus, alignez soigneusement et mettez en quarantaine les sources qui introduisent des erreurs systématiques.
- Négliger les préférences locales. Maintenir des guides de style par locale ; tester des variantes avec des examinateurs natifs ; éviter les paramètres globaux qui remplacent silencieusement les normes locales.
Intégrer la traduction par IA dans les produits
Les choix d'ingénierie façonnent les résultats autant que le choix du modèle. Les API cloud offrent une large couverture linguistique et une capacité élastique ; les modèles auto-hébergés fournissent un contrôle et une gouvernance des données plus strictes ; les hybrides routent le contenu sensible ou à haut risque en interne et envoient le matériel à faible risque à l'extérieur. Le traitement par lots améliore le débit pour de grandes quantités ; les API de streaming réduisent la latence perçue dans les discussions et les environnements en direct. Les clés d'idempotence et les réessais protègent contre la publication en double. L'observabilité est non négociable : stockez des identifiants hachés pour les entrées et les sorties, annotez les erreurs avec des catégories et affichez des tableaux de bord qui combinent des métriques automatiques, des scores humains et des KPI commerciaux (temps de réponse, coût par mot, effort de post-édition).
Pour l'ergonomie des développeurs, faites de la terminologie et de la mémoire de traduction des services de première classe avec des API claires plutôt que des feuilles de calcul éparpillées. Construisez un pipeline de contenu qui ressemble à tout système de données moderne : files d'attente, travailleurs, magasins de fonctionnalités pour glossaires, et travaux d'évaluation qui s'exécutent chaque nuit sur des suites de tests statiques. Créez des portes pour les domaines à haut risque où la publication automatique est désactivée par politique. Et lors de l'utilisation des LLMs, traitez les invites comme une configuration avec versioning, journaux de modifications et chemins de retour ; un petit ajustement d'invite peut changer le ton de manière inattendue.
Les technologies linguistiques apprennent à partir de données qui reflètent les modèles du monde, y compris ses biais. La curation, la dé-duplication et l'audit réduisent les artefacts nuisibles. Lors de la traduction de contenu généré par les utilisateurs, divulguez l'utilisation de la traduction automatique lorsque cela est approprié et respectez le consentement. La provenance des données est importante : les équipes doivent savoir d'où proviennent les corpus d'entraînement et de fine-tuning, quels licences s'appliquent et quelles obligations en découlent. L'accessibilité fait partie du mandat : des variantes en langage clair peuvent être nécessaires dans certains contextes, et les systèmes doivent respecter ces exigences tout aussi strictement qu'ils respectent le ton de la marque.
La traduction par IA, donc, n'est pas un simple appel de modèle mais un système coordonné. Les modèles apprennent la structure interlinguale ; les actifs de données et les contraintes les orientent ; l'estimation de la qualité et les éditeurs humains fournissent des freins et un guidage ; les couches de confidentialité et d'audit rendent le processus fiable ; l'instrumentation montre où s'améliorer ensuite. Lorsque ces éléments sont conçus pour fonctionner ensemble, les organisations ne se contentent pas de déplacer des mots entre les langues—elles préservent l'intention, la clarté et l'identité à travers les produits, les marchés et les supports à l'échelle que la communication moderne exige.
Les systèmes de traduction par IA s'appuient sur des architectures d'apprentissage profond—en particulier les Transformers—pour modéliser des phrases entières comme des représentations contextuelles. Au lieu de s'appuyer sur des probabilités au niveau des mots ou des règles grammaticales définies manuellement, ils apprennent des structures linguistiques implicites à partir de grands corpus parallèles. Cela leur permet de généraliser à travers les domaines et de gérer des entrées colloquiales ou non grammaticales plus efficacement que les systèmes basés sur des règles ou statistiques antérieurs.
Les données d'entraînement sont la base de la capacité d'un traducteur IA. Des corpus bilingues propres, spécifiques au domaine et bien alignés influencent directement la précision et le ton. Le bruit, les désalignements ou les incompatibilités de domaine peuvent propager des erreurs systématiques dans la sortie. Pour des applications à enjeux élevés telles que la traduction juridique ou médicale, des ensembles de données soigneusement sélectionnés et des glossaires validés par des humains sont souvent intégrés dans les étapes de fine-tuning pour maintenir la précision et le contrôle de la terminologie.
Les pipelines de traduction d'entreprise utilisent généralement l'injection de termes et les mémoires de traduction pour garantir une formulation cohérente. Lors du décodage, le système peut imposer dynamiquement les termes requis par le biais d'un décodage contraint. Ces contraintes sont soutenues par des bases de données linguistiques et des systèmes de gestion de la terminologie qui définissent le vocabulaire approuvé par marque, locale et contexte réglementaire. Des outils d'évaluation continue mesurent à quel point le moteur respecte ces termes à travers les mises à jour.
La latence est minimisée grâce à un décodage incrémental, un traitement audio par morceaux et des optimisations d'inférence sur appareil. Au lieu d'attendre une entrée complète, les modèles de streaming génèrent des hypothèses partielles qui se raffinent à mesure que de nouveaux contextes arrivent. Dans la traduction de la parole en direct, les systèmes échangent une petite marge de précision pour la réactivité, en priorisant le timing naturel et l'alignement des segments. La quantification des modèles et l'accélération matérielle réduisent encore les délais de traitement.
Les défis clés incluent la propagation des biais, la confidentialité des données et la traçabilité. Les corpus d'entraînement reflètent souvent des biais sociaux ou culturels qui peuvent réapparaître dans la sortie traduite. Les déploiements responsables anonymisent les données sensibles, mettent en œuvre des pistes d'audit pour les décisions de traduction et permettent un examen humain du contenu à fort impact. La transparence sur la provenance des données et les tests continus des biais deviennent des exigences standard pour les pipelines de traduction par IA conformes.