What Is AI Translation?
What Is AI Translation?
Table of Contents
-
From rules to learned representations - Data, signals, and adaptation
- How production systems actually work
- Measuring quality without illusions
- Context is king
- Speech, latency, and live use
- Privacy, security, and auditability
- Terminology and locale nuance
- Common failure modes—and how teams mitigate them
- Integrating AI translation into products
- Ethics and provenance
- FAQs
AI translation is the automated rendering of meaning from one language into another by learning from data rather than hard-coding grammar rules. It treats translation as a prediction problem: given a sequence of tokens in one language, produce a sequence in the other that preserves sense, tone, register, and formatting. The distinctive feature isn’t just the neural math that generates words; it’s the ecosystem around the models—data pipelines, terminology control, quality estimation, privacy protections, editor workflows, and instrumentation—that turns raw outputs into dependable multilingual communication.
From rules to learned representations
Evolution of machine translation approaches—from rule-based systems to neural representations.
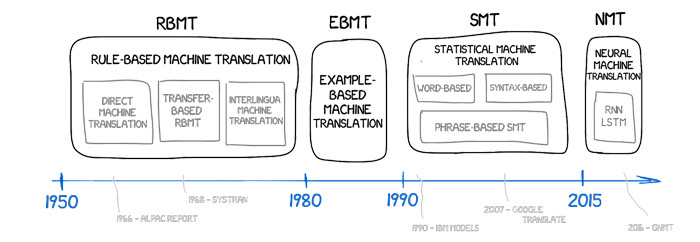
Early systems attempted to encode grammars by hand, mapping parts of speech and phrase structures with elaborate rule sets. Statistical machine translation replaced rules with probabilities over words and phrases extracted from aligned corpora. The current standard is neural machine translation (NMT), where a single network learns to represent the source sentence as dense vectors and to decode a target sentence token by token. Modern NMT is usually built on the Transformer architecture. Its attention mechanism lets the model weigh relationships across the entire sequence, capturing long-range dependencies and flexible word order. To keep vocabularies manageable while covering inflection and rare names, tokenization relies on subword units such as Byte-Pair Encoding or SentencePiece.
Large language models (LLMs) extend this approach. Trained on massive multilingual corpora and instruction-tuned for general reasoning, they can translate as one capability among many, handling messy input like partial sentences, mixed markup, or chatty support logs. Their versatility is helpful, but open-ended generation brings challenges: paraphrase where precision is required, or confident assertions of details that were never present in the source. Production systems often pair a strong NMT engine with an LLM stage that adjusts tone while constrained decoding and term injection protect critical wording.
High-quality parallel corpora are the backbone. Courts, parliaments, subtitles, developer portals, and bilingual websites provide aligned sentence pairs for supervised learning. Monolingual text matters too. With back-translation, target-language sentences are translated into the source to synthesize additional pairs, improving fluency and coverage in low-resource directions. Self-training variants and noisy-channel objectives further bias models toward natural target output.
Domain adaptation is where generic competence becomes business value. A general model that performs well on news and web pages can falter on legal boilerplate, clinical leaflets, or patent abstracts. Fine-tuning on even modest amounts of in-domain material—augmented by terminology lists and translation memories—can shift style and terminology dramatically. Parameter-efficient techniques (adapters, LoRA) let teams maintain multiple domain personalities without retraining the whole model. Over time, post-editor corrections and ratings become training signals: feedback loops that move the system toward an organization’s preferred voice.
How production systems actually work
Real deployments start before any token is generated. Content is normalized, segmented, and language-detected; placeholders and markup are identified so they can be preserved. Highly repeatable strings—UI labels, product codes, email templates—are recognized early and often bypass translation or are constrained to exact variants. The engine encodes the source, decodes the target with beam search or constrained sampling, and detokenizes to restore casing and spacing. Post-processing re-inserts tags, numbers, and named entities. A quality estimation model predicts confidence, routing low-confidence segments to human editors while allowing high-confidence ones to publish when latency matters.
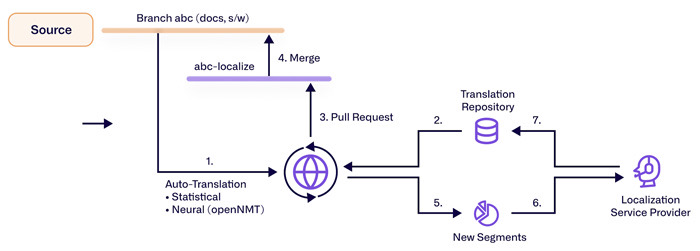
A few levers define the translation characteristics:
- Constrained decoding: required terms must appear, with inflectional flexibility for morphologically rich languages.
- Term injection and memories: preferred variants and previously approved sentences steer outputs toward consistency.
- Risk routing: quality estimation sets thresholds for auto-publish vs. post-edit, balancing cost, speed, and accuracy.
Computer-assisted translation tools provide the cockpit for editors. Suggestions update as they type; diffs measure post-editing effort; keystroke and time metrics show where models struggle. These traces inform training data selection and model updates. Instrumentation is essential: latency, throughput, error types, and editor effort are tracked by locale and domain. Teams can drill from a dashboard metric to the exact sentence that caused a regression.
Measuring quality without illusions
Automatic metrics provide fast feedback. BLEU and chrF measure n-gram overlap or character-level similarity; learned metrics like COMET correlate better with human judgments by comparing outputs and references through neural encoders. Reference-free quality estimation predicts a score and even error spans using only the source and hypothesis, enabling real-time routing. Yet none of these replace human review. Linguists check adequacy (meaning preserved) and fluency (naturalness), and they apply domain-specific checklists: does the output respect brand voice, legal phrasing, contraindication wording, and locale conventions for names, addresses, and decimals? Good programs mix automated dashboards with periodic blind human evaluations, seeded with difficult phenomena such as long-distance agreement, idioms, and code-mixed slang.
Many translation errors are failures of context. Pronouns, ellipsis, and discourse links require awareness beyond the sentence. Document-level models condition on surrounding sentences; retrieval-augmented translation fetches relevant segments from earlier in the document, style guides, or ticket histories and attends to them during decoding. In support chat, incremental decoding respects speaker turns and maintains consistent register per participant. In marketing copy, small choices—honorifics, formality, rhythm—can matter more than literal fidelity, and these are often governed by style sheets and locale-specific rules injected into prompts or decoding constraints.
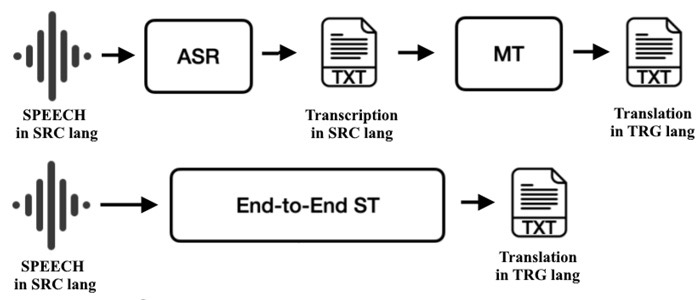
Speech translation introduces timing and prosody. Cascaded systems perform ASR → text MT → TTS; each stage can be tuned separately, and timestamps allow subtitle alignment. End-to-end speech-to-text translation maps audio directly into another language’s text, reducing compounding errors and sometimes preserving phrasing better. Live scenarios emphasize latency. Systems segment audio into small chunks, deliver partial hypotheses quickly, and revise them as confidence grows. Careful punctuation and disfluency handling improves readability in captions and prevents ambiguity in instructions where a missing comma can change meaning.
Privacy, security, and auditability
Translation often touches sensitive content: user messages, internal docs, health records, contracts. Deployments respond with technical and procedural controls. Inputs and outputs are encrypted in transit and at rest; retention windows are minimized; personally identifiable information is masked before processing and reinserted after. Access controls restrict who can view raw content and model outputs. For regulated industries, audit logs record model versions, prompts, decoding parameters, editor actions, and approval steps to reconstruct how a sentence reached publication. Content filters detect risky categories such as hate or self-harm; flagged passages may require an additional human reviewer even if the language itself looks fluent.
Terminology is often where correctness meets identity. A product team might insist on “Sign in” rather than “Log in,” or on a specific phrasing for a warranty clause. The system enforces these choices through hard constraints, soft biases, and validation checks that run after generation. Translation memories supply exact and fuzzy matches so repeated content stays consistent and editors avoid redoing work. Locale details that seem minor—address order, decimal separators, date formats, title capitalization—add up to credibility. Names present special cases: transliteration policies differ by market, and some brands are always kept in Latin script while others are localized.
Common failure modes—and how teams mitigate them
-
Numbers and codes drifting during generation. Copy mechanisms and post-validators ensure product codes, prices, and unit conversions remain intact. - Ambiguous short strings. Add metadata (screen name, audience) to disambiguate or route to humans; keep mini-glossaries for UI components.
- Over-paraphrase from general LLMs. Use constrained decoding, term enforcement, and a domain-tuned NMT pass before stylistic refinement.
- Noisy or misaligned training data. Curate corpora, align carefully, and quarantine sources that introduce systematic errors.
- Neglecting locale preferences. Maintain per-locale style guides; test variants with native reviewers; avoid global settings that silently override local norms.
Integrating AI translation into products
Engineering choices shape outcomes as much as model choice. Cloud APIs offer broad language coverage and elastic capacity; self-hosted models provide control and tighter data governance; hybrids route sensitive or high-risk content internally and send low-risk material outside. Batch processing improves throughput for large drops; streaming APIs reduce perceived latency in chat and live settings. Idempotency keys and retries protect against duplicate publishing. Observability is non-negotiable: store hashed identifiers for inputs and outputs, annotate errors with categories, and surface dashboards that combine automatic metrics, human scores, and business KPIs (turnaround time, cost per word, post-editing effort).
For developer ergonomics, make terminology and translation memory first-class services with clear APIs rather than scattered spreadsheets. Build a content pipeline that looks like any modern data system: queues, workers, feature stores for glossaries, and evaluation jobs that run nightly on static test suites. Create gates for high-risk domains where automatic publishing is disabled by policy. And when using LLMs, treat prompts as configuration with versioning, change logs, and rollback paths; a small prompt tweak can shift tone in unexpected ways.
Language technologies learn from data that reflects the world’s patterns, including its biases. Curation, deduplication, and auditing reduce harmful artifacts. When translating user-generated content, disclose the use of machine translation where appropriate and respect consent. Data provenance matters: teams should know where training and fine-tuning corpora originated, what licenses apply, and what obligations follow. Accessibility is part of the remit: plain-language variants may be necessary in some contexts, and systems should honor those requirements just as strictly as they honor brand tone.
AI translation, then, is not a single model call but a coordinated system. Models learn cross-lingual structure; data assets and constraints steer them; quality estimation and human editors provide brakes and steering; privacy and audit layers make the process trustworthy; instrumentation shows where to improve next. When those pieces are designed to work together, organizations don’t just move words between languages—they preserve intent, clarity, and identity across products, markets, and mediums at the scale modern communication demands.
AI translation systems rely on deep learning architectures—especially Transformers—to model entire sentences as contextual representations. Instead of relying on word-level probabilities or manually defined grammar rules, they learn implicit linguistic structures from large parallel corpora. This allows them to generalize across domains and handle colloquial or ungrammatical input more effectively than earlier rule-based or statistical systems.
Training data is the foundation of an AI translator’s capability. Clean, domain-specific, and well-aligned bilingual corpora directly influence accuracy and tone. Noise, misalignments, or domain mismatch can propagate systematic errors into output. For high-stakes applications such as legal or medical translation, curated datasets and human-validated glossaries are often integrated into fine-tuning stages to maintain precision and terminology control.
Enterprise translation pipelines typically use term injection and translation memories to guarantee consistent phrasing. During decoding, the system can enforce required terms dynamically through constrained decoding. These constraints are backed by linguistic databases and terminology management systems that define approved vocabulary by brand, locale, and regulatory context. Continuous evaluation tools measure how consistently the engine respects those terms across updates.
Latency is minimized through incremental decoding, chunked audio processing, and on-device inference optimizations. Instead of waiting for complete input, streaming models generate partial hypotheses that refine as new context arrives. In live speech translation, systems trade a small accuracy margin for responsiveness, prioritizing natural timing and segment alignment. Model quantization and hardware acceleration further reduce processing delays.
Key challenges include bias propagation, data privacy, and traceability. Training corpora often reflect social or cultural biases that can reappear in translated output. Responsible deployments anonymize sensitive data, implement audit trails for translation decisions, and allow human review of high-impact content. Transparency in data provenance and continual bias testing are becoming standard requirements for compliant AI translation pipelines.