Was ist KI-Übersetzung?
Was ist KI-Übersetzung?
Inhaltsverzeichnis
-
Von Regeln zu gelernten Darstellungen - Daten, Signale und Anpassung
- Wie Produktionssysteme tatsächlich funktionieren
- Qualität ohne Illusionen messen
- Kontext ist König
- Sprache, Latenz und Live-Nutzung
- Datenschutz, Sicherheit und Nachvollziehbarkeit
- Terminologie und lokale Nuancen
- Häufige Fehlerarten—und wie Teams sie mindern
- Integration von KI-Übersetzung in Produkte
- Ethik und Herkunft
- FAQs
KI-Übersetzung ist die automatisierte Übertragung von Bedeutung aus einer Sprache in eine andere, indem aus Daten gelernt wird, anstatt Grammatikregeln fest zu codieren. Sie betrachtet Übersetzung als ein Vorhersageproblem: Gegeben eine Sequenz von Tokens in einer Sprache, erzeugen Sie eine Sequenz in der anderen, die Sinn, Ton, Register und Formatierung bewahrt. Das Unterscheidungsmerkmal ist nicht nur die neuronale Mathematik, die Wörter generiert; es ist das Ökosystem um die Modelle—Datenpipelines, Terminologiekontrolle, Qualitätsbewertung, Datenschutz, Redakteurs-Workflows und Instrumentierung—das rohe Ausgaben in zuverlässige mehrsprachige Kommunikation verwandelt.
Von Regeln zu gelernten Darstellungen
Entwicklung der Ansätze zur maschinellen Übersetzung—von regelbasierten Systemen zu neuronalen Darstellungen.
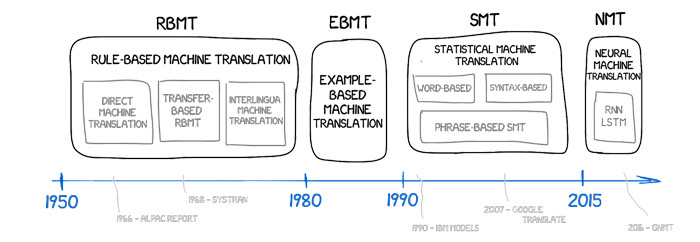
Frühe Systeme versuchten, Grammatiken von Hand zu kodieren, indem sie Wortarten und Satzstrukturen mit aufwendigen Regelsets abbildeten. Die statistische maschinelle Übersetzung ersetzte Regeln durch Wahrscheinlichkeiten über Wörter und Phrasen, die aus ausgerichteten Korpora extrahiert wurden. Der aktuelle Standard ist die neuronale maschinelle Übersetzung (NMT), bei der ein einzelnes Netzwerk lernt, den Quellsatz als dichte Vektoren darzustellen und einen Zielsatz tokenweise zu dekodieren. Moderne NMT basiert normalerweise auf der Transformer-Architektur. Ihr Aufmerksamkeitsmechanismus ermöglicht es dem Modell, Beziehungen über die gesamte Sequenz hinweg zu gewichten, wodurch langfristige Abhängigkeiten und flexible Wortreihenfolgen erfasst werden. Um die Wortschätze handhabbar zu halten und gleichzeitig Flexion und seltene Namen abzudecken, verlässt sich die Tokenisierung auf Subwort-Einheiten wie Byte-Pair-Encoding oder SentencePiece.
Große Sprachmodelle (LLMs) erweitern diesen Ansatz. Sie werden auf massiven mehrsprachigen Korpora trainiert und für allgemeines Denken optimiert, sodass sie Übersetzungen als eine von vielen Fähigkeiten durchführen können und mit unordentlichen Eingaben wie unvollständigen Sätzen, gemischten Markups oder gesprächigen Support-Protokollen umgehen können. Ihre Vielseitigkeit ist hilfreich, aber die offene Generierung bringt Herausforderungen mit sich: Paraphrasierung, wo Präzision erforderlich ist, oder selbstbewusste Behauptungen von Details, die im Quelltext nie vorhanden waren. Produktionssysteme kombinieren oft eine starke NMT-Engine mit einer LLM-Phase, die den Ton anpasst, während die eingeschränkte Dekodierung und die Termininjektion kritische Formulierungen schützen.
Hochwertige parallele Korpora sind das Rückgrat. Gerichte, Parlamente, Untertitel, Entwicklerportale und zweisprachige Websites bieten ausgerichtete Satzpaare für das überwachte Lernen. Monolinguale Texte sind ebenfalls wichtig. Mit Rückübersetzung werden Zielsprachensätze in die Ausgangssprache übersetzt, um zusätzliche Paare zu synthetisieren, was die Flüssigkeit und Abdeckung in ressourcenarmen Richtungen verbessert. Selbsttrainingsvarianten und Ziele des Rauschkanals neigen Modelle weiter in Richtung natürlicher Zielausgaben.
Domänenanpassung ist der Punkt, an dem generische Kompetenz zu Geschäftswert wird. Ein allgemeines Modell, das gut auf Nachrichten und Webseiten funktioniert, kann bei rechtlichen Standardtexten, klinischen Broschüren oder Patentabstrakten versagen. Feinabstimmung auf selbst bescheidenen Mengen an In-Domain-Material—unterstützt durch Terminologielisten und Übersetzungsspeicher—kann Stil und Terminologie dramatisch verändern. Parameter-effiziente Techniken (Adapter, LoRA) ermöglichen es Teams, mehrere Domänenpersönlichkeiten zu pflegen, ohne das gesamte Modell neu zu trainieren. Im Laufe der Zeit werden Korrekturen und Bewertungen von Post-Editoren zu Trainingssignalen: Feedback-Schleifen, die das System in Richtung der bevorzugten Stimme einer Organisation bewegen.
Wie Produktionssysteme tatsächlich funktionieren
Echte Bereitstellungen beginnen, bevor ein Token generiert wird. Inhalte werden normalisiert, segmentiert und die Sprache erkannt; Platzhalter und Markup werden identifiziert, damit sie erhalten bleiben können. Hochgradig wiederholbare Strings—UI-Labels, Produktcodes, E-Mail-Vorlagen—werden frühzeitig erkannt und oft von der Übersetzung ausgeschlossen oder auf genaue Varianten beschränkt. Die Engine kodiert die Quelle, dekodiert das Ziel mit Beam-Suche oder eingeschränkter Stichprobenahme und detokenisiert, um Groß- und Kleinschreibung sowie Abstände wiederherzustellen. Die Nachbearbeitung fügt Tags, Zahlen und benannte Entitäten wieder ein. Ein Qualitätsbewertungsmodell sagt das Vertrauen voraus und leitet Segmente mit niedrigem Vertrauen an menschliche Redakteure weiter, während hochvertrauenswürdige Segmente veröffentlicht werden, wenn Latenz wichtig ist.
Einige Hebel definieren die Übersetzungsmerkmale:
- Eingeschränkte Dekodierung: erforderliche Begriffe müssen erscheinen, mit flexibler Flexion für morphologisch reiche Sprachen.
- Termininjektion und -speicher: bevorzugte Varianten und zuvor genehmigte Sätze lenken Ausgaben in Richtung Konsistenz.
- Risikorouting: Qualitätsbewertung setzt Schwellenwerte für Auto-Publikation vs. Nachbearbeitung, um Kosten, Geschwindigkeit und Genauigkeit auszubalancieren.
Computerunterstützte Übersetzungstools bieten das Cockpit für Redakteure. Vorschläge aktualisieren sich, während sie tippen; Diffs messen den Aufwand für die Nachbearbeitung; Tastenanschläge und Zeitmetriken zeigen, wo Modelle Schwierigkeiten haben. Diese Spuren informieren die Auswahl der Trainingsdaten und Modellaktualisierungen. Instrumentierung ist unerlässlich: Latenz, Durchsatz, Fehlerarten und Redakteursaufwand werden nach Region und Domäne verfolgt. Teams können von einer Dashboard-Metrik zu dem genauen Satz bohren, der eine Regression verursacht hat.
Qualität ohne Illusionen messen
Automatische Metriken bieten schnelles Feedback. BLEU und chrF messen n-Gramm-Überlappung oder Zeichenebene Ähnlichkeit; erlernte Metriken wie COMET korrelieren besser mit menschlichen Urteilen, indem sie Ausgaben und Referenzen durch neuronale Encoder vergleichen. Referenzfreie Qualitätsbewertung sagt einen Score und sogar Fehlerbereiche voraus, indem nur die Quelle und Hypothese verwendet werden, was eine Echtzeit-Routing ermöglicht. Doch keine dieser Methoden ersetzt die menschliche Überprüfung. Linguisten überprüfen die Angemessenheit (Bedeutung erhalten) und Flüssigkeit (Natürlichkeit) und wenden domänenspezifische Checklisten an: Achtet die Ausgabe auf die Markenstimme, rechtliche Formulierungen, Formulierungen zu Gegenanzeigen und lokale Konventionen für Namen, Adressen und Dezimalzahlen? Gute Programme kombinieren automatisierte Dashboards mit periodischen blinden menschlichen Bewertungen, die mit schwierigen Phänomenen wie Fernabstimmungen, Idiomen und code-mischendem Slang gesät sind.
Viele Übersetzungsfehler sind Kontextversagen. Pronomen, Ellipsen und Diskursverbindungen erfordern ein Bewusstsein über den Satz hinaus. Dokumentenebenenmodelle konditionieren auf umgebende Sätze; abrufunterstützte Übersetzung holt relevante Segmente aus früheren Dokumenten, Stilrichtlinien oder Ticketverläufen und bezieht sie während der Dekodierung ein. Im Support-Chat respektiert inkrementelle Dekodierung die Sprecherwechsel und hält das Register pro Teilnehmer konsistent. In Marketingtexten können kleine Entscheidungen—Ehrenbezeichnungen, Formalität, Rhythmus—wichtiger sein als wörtliche Treue, und diese werden oft durch Stilblätter und lokale spezifische Regeln, die in Eingabeaufforderungen oder Dekodierungsbeschränkungen injiziert werden, geregelt.
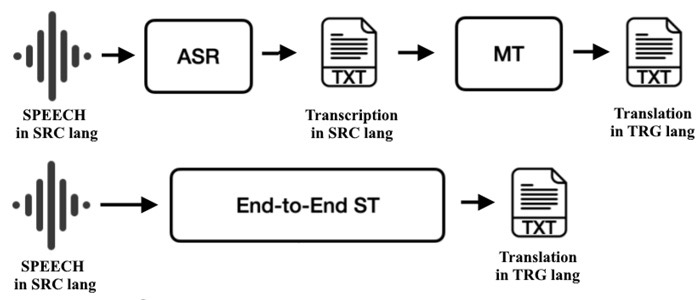
Sprache, Latenz und Live-Nutzung
Die Sprachübersetzung bringt Timing und Prosodie mit sich. Kaskadierte Systeme führen ASR → Text MT → TTS aus; jede Phase kann separat optimiert werden, und Zeitstempel ermöglichen die Ausrichtung von Untertiteln. Die End-to-End-Sprach-zu-Text-Übersetzung kartiert Audio direkt in den Text einer anderen Sprache, wodurch kumulative Fehler reduziert und manchmal die Formulierung besser erhalten bleibt. Live-Szenarien betonen die Latenz. Systeme segmentieren Audio in kleine Stücke, liefern schnell partielle Hypothesen und überarbeiten sie, wenn das Vertrauen wächst. Sorgfältige Interpunktion und Umgang mit Unflüssigkeiten verbessern die Lesbarkeit in Untertiteln und verhindern Mehrdeutigkeiten in Anweisungen, bei denen ein fehlendes Komma die Bedeutung ändern kann.
Datenschutz, Sicherheit und Nachvollziehbarkeit
Übersetzungen betreffen oft sensible Inhalte: Benutzernachrichten, interne Dokumente, Gesundheitsakten, Verträge. Bereitstellungen reagieren mit technischen und verfahrenstechnischen Kontrollen. Eingaben und Ausgaben werden während der Übertragung und im Ruhezustand verschlüsselt; Aufbewahrungsfristen werden minimiert; personenbezogene Daten werden vor der Verarbeitung maskiert und danach wieder eingefügt. Zugriffskontrollen beschränken, wer Rohinhalte und Modellausgaben einsehen kann. Für regulierte Branchen protokollieren Audit-Logs Modellversionen, Eingabeaufforderungen, Dekodierungsparameter, Redakteursaktionen und Genehmigungsschritte, um nachzuvollziehen, wie ein Satz veröffentlicht wurde. Inhaltsfilter erkennen riskante Kategorien wie Hass oder Selbstverletzung; markierte Passagen können einen zusätzlichen menschlichen Prüfer erfordern, selbst wenn die Sprache selbst flüssig aussieht.
Terminologie und lokale Nuancen
Terminologie ist oft der Punkt, an dem Korrektheit auf Identität trifft. Ein Produktteam könnte auf „Anmelden“ anstelle von „Einloggen“ bestehen oder auf eine spezifische Formulierung für eine Garantie-Klausel. Das System erzwingt diese Entscheidungen durch harte Einschränkungen, weiche Vorurteile und Validierungsprüfungen, die nach der Generierung durchgeführt werden. Übersetzungsspeicher liefern exakte und unscharfe Übereinstimmungen, sodass wiederholte Inhalte konsistent bleiben und Redakteure ihre Arbeit nicht wiederholen müssen. Lokale Details, die geringfügig erscheinen—Adressreihenfolge, Dezimaltrennzeichen, Datumsformate, Titel-Großschreibung—addieren sich zur Glaubwürdigkeit. Namen stellen besondere Fälle dar: Transliterationsrichtlinien unterscheiden sich je nach Markt, und einige Marken werden immer in lateinischer Schrift gehalten, während andere lokalisiert werden.
Häufige Fehlerarten—und wie Teams sie mindern
-
Zahlen und Codes, die während der Generierung abdriften. Kopiermechanismen und Nachvalidierer stellen sicher, dass Produktcodes, Preise und Maßeinheiten intakt bleiben. - Mehrdeutige kurze Strings. Fügen Sie Metadaten (Bildschirmname, Publikum) hinzu, um zu disambiguieren oder an Menschen weiterzuleiten; führen Sie Mini-Glossare für UI-Komponenten.
- Überparaphrasierung von allgemeinen LLMs. Verwenden Sie eingeschränkte Dekodierung, Terminerzwingung und einen domänenspezifischen NMT-Durchgang vor der stilistischen Verfeinerung.
- Rauschende oder nicht ausgerichtete Trainingsdaten. Kuratieren Sie Korpora, richten Sie sie sorgfältig aus und quarantänisieren Sie Quellen, die systematische Fehler einführen.
- Vernachlässigung lokaler Präferenzen. Pflegen Sie stilistische Leitfäden pro Region; testen Sie Varianten mit einheimischen Prüfern; vermeiden Sie globale Einstellungen, die stillschweigend lokale Normen überschreiben.
Integration von KI-Übersetzung in Produkte
Ingenieurauswahl prägt die Ergebnisse ebenso wie die Modellwahl. Cloud-APIs bieten breite Sprachabdeckung und elastische Kapazität; selbstgehostete Modelle bieten Kontrolle und engere Datenverwaltung; Hybride leiten sensible oder risikobehaftete Inhalte intern und senden risikoarme Materialien nach außen. Batch-Verarbeitung verbessert den Durchsatz für große Mengen; Streaming-APIs reduzieren die wahrgenommene Latenz in Chat- und Live-Einstellungen. Idempotenzschlüssel und Wiederholungen schützen vor doppelter Veröffentlichung. Beobachtbarkeit ist nicht verhandelbar: Speichern Sie gehashte Identifikatoren für Eingaben und Ausgaben, annotieren Sie Fehler mit Kategorien und zeigen Sie Dashboards an, die automatische Metriken, menschliche Bewertungen und geschäftliche KPIs (Durchlaufzeit, Kosten pro Wort, Aufwand für Nachbearbeitung) kombinieren.
Für die Ergonomie der Entwickler sollten Terminologie und Übersetzungsspeicher erstklassige Dienste mit klaren APIs sein, anstatt verstreute Tabellenkalkulationen. Erstellen Sie eine Inhalts-Pipeline, die wie jedes moderne Datensystem aussieht: Warteschlangen, Arbeiter, Feature-Stores für Glossare und Evaluierungsjobs, die nachts auf statischen Test-Suiten ausgeführt werden. Erstellen Sie Tore für risikobehaftete Domänen, in denen die automatische Veröffentlichung durch Richtlinien deaktiviert ist. Und wenn Sie LLMs verwenden, behandeln Sie Eingabeaufforderungen als Konfiguration mit Versionierung, Änderungsprotokollen und Rückrollpfaden; eine kleine Anpassung der Eingabeaufforderung kann den Ton auf unerwartete Weise verändern.
Sprachtechnologien lernen aus Daten, die die Muster der Welt widerspiegeln, einschließlich ihrer Vorurteile. Kuratierung, Duplikation und Prüfung reduzieren schädliche Artefakte. Bei der Übersetzung von nutzergenerierten Inhalten sollte die Verwendung von maschineller Übersetzung, wo angemessen, offengelegt und die Zustimmung respektiert werden. Die Herkunft der Daten ist wichtig: Teams sollten wissen, woher die Trainings- und Feinabstimmungs-Korpora stammen, welche Lizenzen gelten und welche Verpflichtungen folgen. Barrierefreiheit ist Teil des Auftrags: Varianten in einfacher Sprache können in einigen Kontexten notwendig sein, und Systeme sollten diese Anforderungen ebenso strikt einhalten wie sie den Markenton respektieren.
KI-Übersetzung ist also kein einzelner Modellaufruf, sondern ein koordiniertes System. Modelle lernen übergreifende sprachliche Strukturen; Datenressourcen und Einschränkungen lenken sie; Qualitätsbewertung und menschliche Redakteure bieten Bremsen und Steuerung; Datenschutz- und Prüfungsmaßnahmen machen den Prozess vertrauenswürdig; Instrumentierung zeigt, wo man als Nächstes verbessern kann. Wenn diese Teile so gestaltet sind, dass sie zusammenarbeiten, bewegen Organisationen nicht nur Wörter zwischen Sprachen—sie bewahren Absicht, Klarheit und Identität über Produkte, Märkte und Medien hinweg in dem Maßstab, den die moderne Kommunikation erfordert.
KI-Übersetzungssysteme basieren auf tiefen Lernarchitekturen—insbesondere Transformatoren—um ganze Sätze als kontextuelle Darstellungen zu modellieren. Anstatt sich auf Wortwahrscheinlichkeiten oder manuell definierte Grammatikregeln zu verlassen, lernen sie implizite linguistische Strukturen aus großen parallelen Korpora. Dies ermöglicht es ihnen, über Domänen hinweg zu generalisieren und umgangssprachliche oder ungrammatische Eingaben effektiver zu verarbeiten als frühere regelbasierte oder statistische Systeme.
Trainingsdaten sind die Grundlage der Fähigkeiten eines KI-Übersetzers. Saubere, domänenspezifische und gut ausgerichtete zweisprachige Korpora beeinflussen direkt die Genauigkeit und den Ton. Rauschen, Fehlanpassungen oder Domänenunterschiede können systematische Fehler in die Ausgabe einbringen. Für Anwendungen mit hohen Einsätzen, wie rechtliche oder medizinische Übersetzungen, werden kuratierte Datensätze und menschlich validierte Glossare oft in die Feinabstimmungsphasen integriert, um Präzision und Terminologiekontrolle aufrechtzuerhalten.
Unternehmensübersetzungspipelines verwenden typischerweise Termininjektion und Übersetzungsspeicher, um konsistente Formulierungen zu garantieren. Während der Dekodierung kann das System erforderliche Begriffe dynamisch durch eingeschränkte Dekodierung durchsetzen. Diese Einschränkungen werden durch linguistische Datenbanken und Terminologiemanagementsysteme unterstützt, die genehmigtes Vokabular nach Marke, Region und regulatorischem Kontext definieren. Kontinuierliche Bewertungswerkzeuge messen, wie konsistent die Engine diese Begriffe über Updates hinweg respektiert.
Latenz wird durch inkrementelle Dekodierung, chunkierte Audioverarbeitung und Optimierungen der Inferenz auf dem Gerät minimiert. Anstatt auf vollständige Eingaben zu warten, erzeugen Streaming-Modelle partielle Hypothesen, die sich verfeinern, wenn neuer Kontext eintrifft. In der Live-Sprachübersetzung tauschen Systeme eine kleine Genauigkeitsmarge gegen Reaktionsfähigkeit ein und priorisieren natürliches Timing und Segmentausrichtung. Modellquantisierung und Hardwarebeschleunigung reduzieren zudem die Verarbeitungsverzögerungen.
Wesentliche Herausforderungen sind die Weitergabe von Vorurteilen, Datenschutz und Nachvollziehbarkeit. Trainingskorpora spiegeln oft soziale oder kulturelle Vorurteile wider, die in der übersetzten Ausgabe wieder auftauchen können. Verantwortungsvolle Bereitstellungen anonymisieren sensible Daten, implementieren Prüfprotokolle für Übersetzungsentscheidungen und ermöglichen die menschliche Überprüfung von Inhalten mit hoher Auswirkung. Transparenz in der Herkunft der Daten und kontinuierliche Vorurteilstests werden zu Standardanforderungen für konforme KI-Übersetzungspipelines.